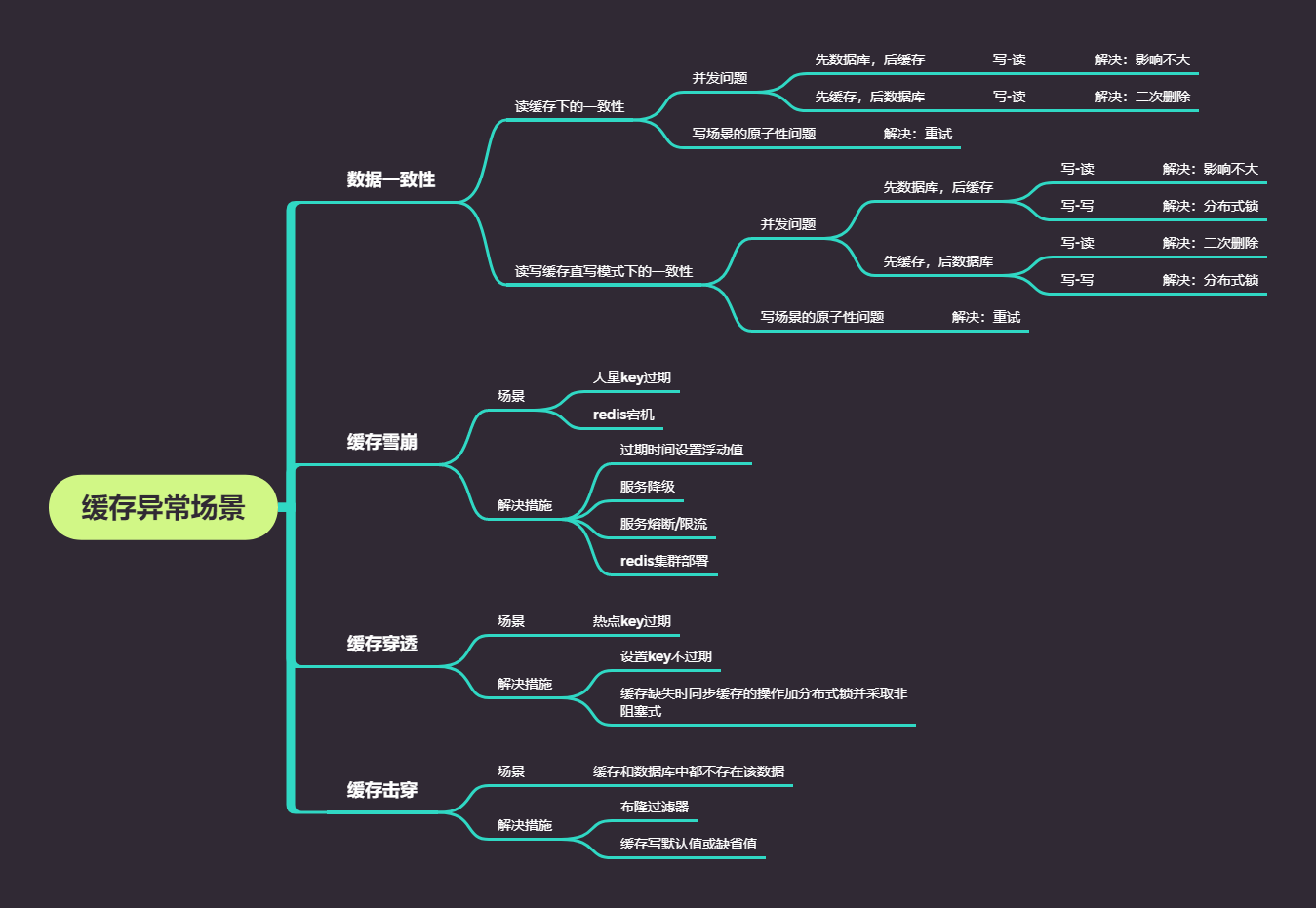
应用redis缓存时,会发生如下问题:
- 缓存和数据库中数据不一致
- 缓存雪崩
- 缓存击穿
- 缓存穿透
1.缓存和数据库中数据不一致
数据一致性包含两种情况:
- 第一种:缓存中有数据,且数据和数据库中一致
- 第二种:缓存中没有数据,且数据库的数据是最新的
1.1.发生场景
根据缓存的三种类型,来详细讲解下不一致可能出现的情形
(1)读缓存
-
新增操作:新增数据,数据会直接写入到数据库,不涉及缓存操作,因此不会出现不一致的情形,且数据符合一致性的第一种情形
-
删改操作:既要更新数据库,也需要删除缓存中的数据。两个操作如果无法保住原子性,则会出现数据不一致的问题
如下图:

-
并发场景下的数据不一致
(2)读写缓存-直写场景
针对这种缓存类型的数据不一致的问题,大致与读场景相同,其实二者的区别也就是写请求的处理,读写缓存针对写请求是同步缓存,而读缓存是删除缓存,因此读写缓存场景下,新增的不一致的类型包括:新增请求,并发下的写写(执行顺序导致)请求
写+读场景下,如果缓存不存在怎么办?
可能的问题:假设写请求W,读请求R
| 时间 | W | R |
|---|
| T1 | | 读取缓存无数据,读取DB |
| T2 | 更新DB | |
| T3 | 删除缓存/更新缓存 | |
| T4 | | 写入读取的数据入缓存 |
虽然这种场景会出现问题,不过由于读取缓存+写入读取的数据入缓存的耗时比更新DB的耗时小的多,因此发生的概率极低,不过不排除R线程由于GC导致STW中断
1.2.如何解决数据不一致
(1)重试机制
通过引入消息队列或者代码中手写重试代码,如果重试之后仍然失败则抛错
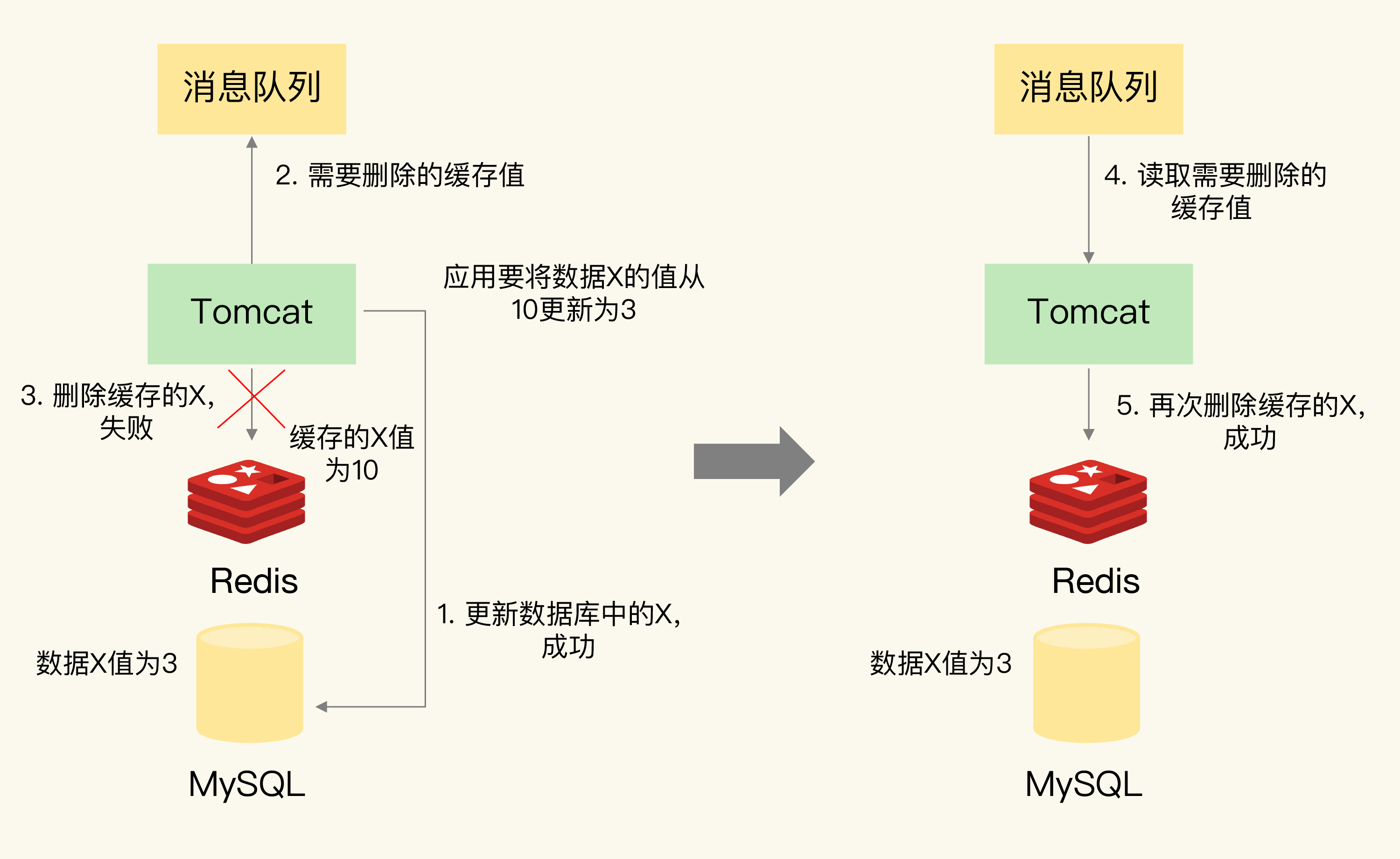
(2)针对并发场景下的读缓存的
先删除缓存,再更新数据库:
- (写+读)延迟双删:线程A再更新完数据库之后,再sleep一会再删除缓存一次,具体sleep时间更新线程读数据+写缓存的时间(其实就是上述线程B的耗时)
先更新数据库,再更新缓存:
(3)针对并发场景下的读写缓存的
先更新缓存,再更新数据库:
- (读+写)由于对业务的影响都不大,因此无需特殊处理
- (写+写)写请求进来时,针对同一个资源的修改操作,先加分布式锁,这样同一时间只允许一个线程去更新数据库和缓存,没有拿到锁的线程把操作放入到队列中,延时处理
先更新数据库,再更新缓存
- (读+写)由于对业务的影响都不大,因此无需特殊处理
- (写+写)同上写+写
写+写其实就是更新覆盖的场景,上述解决措施采取的悲观锁,这里其实也可以采取乐观锁的方式
1.3.先更新库还是先更新缓存的取舍
先总结下表:
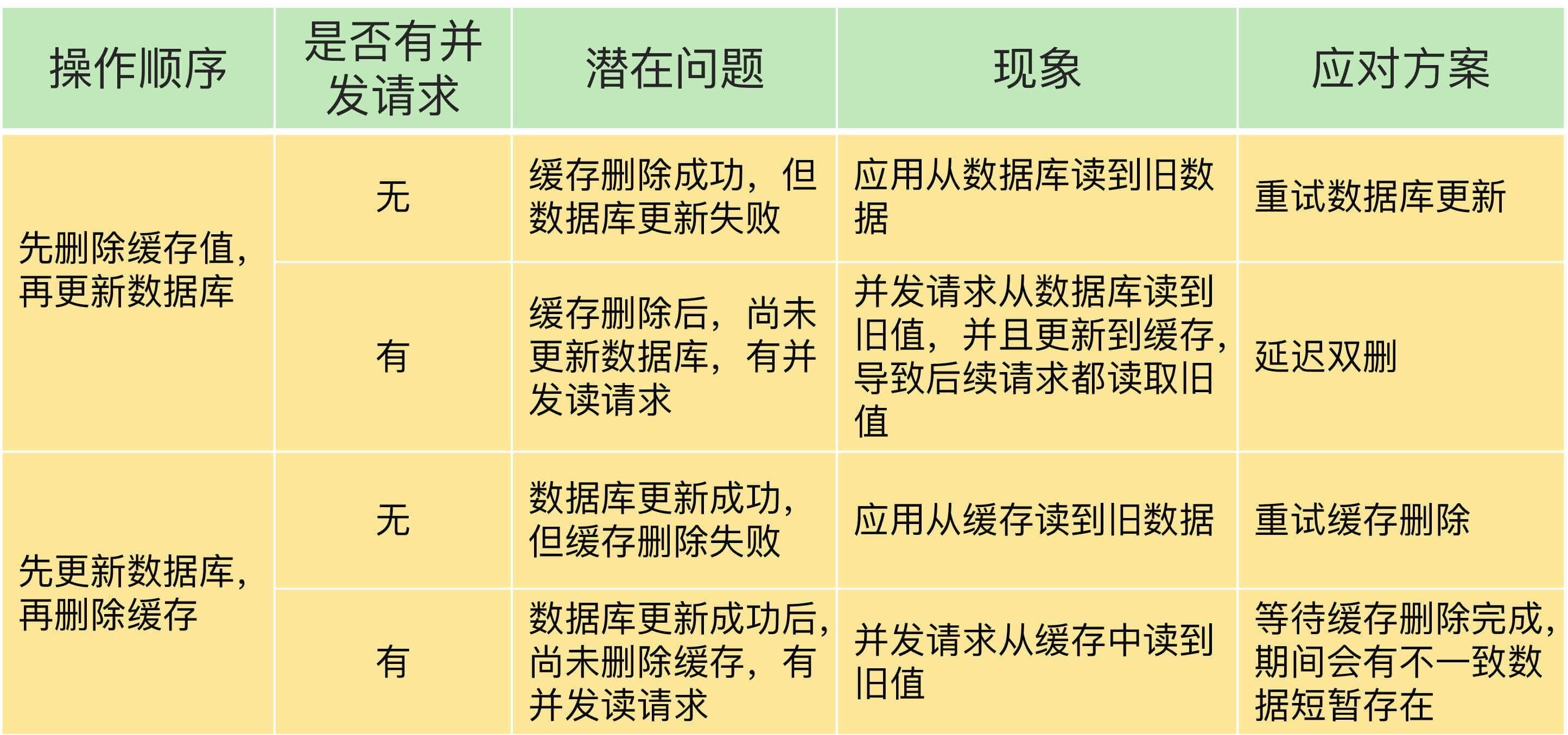
建议优先更新库再删除缓存,好处如下:
- 先删除缓存再更新库,可能会导致数据缺失给数据库带来压力
- 先删除缓存再删库解决办法的延迟双删的sleep时间不好把握
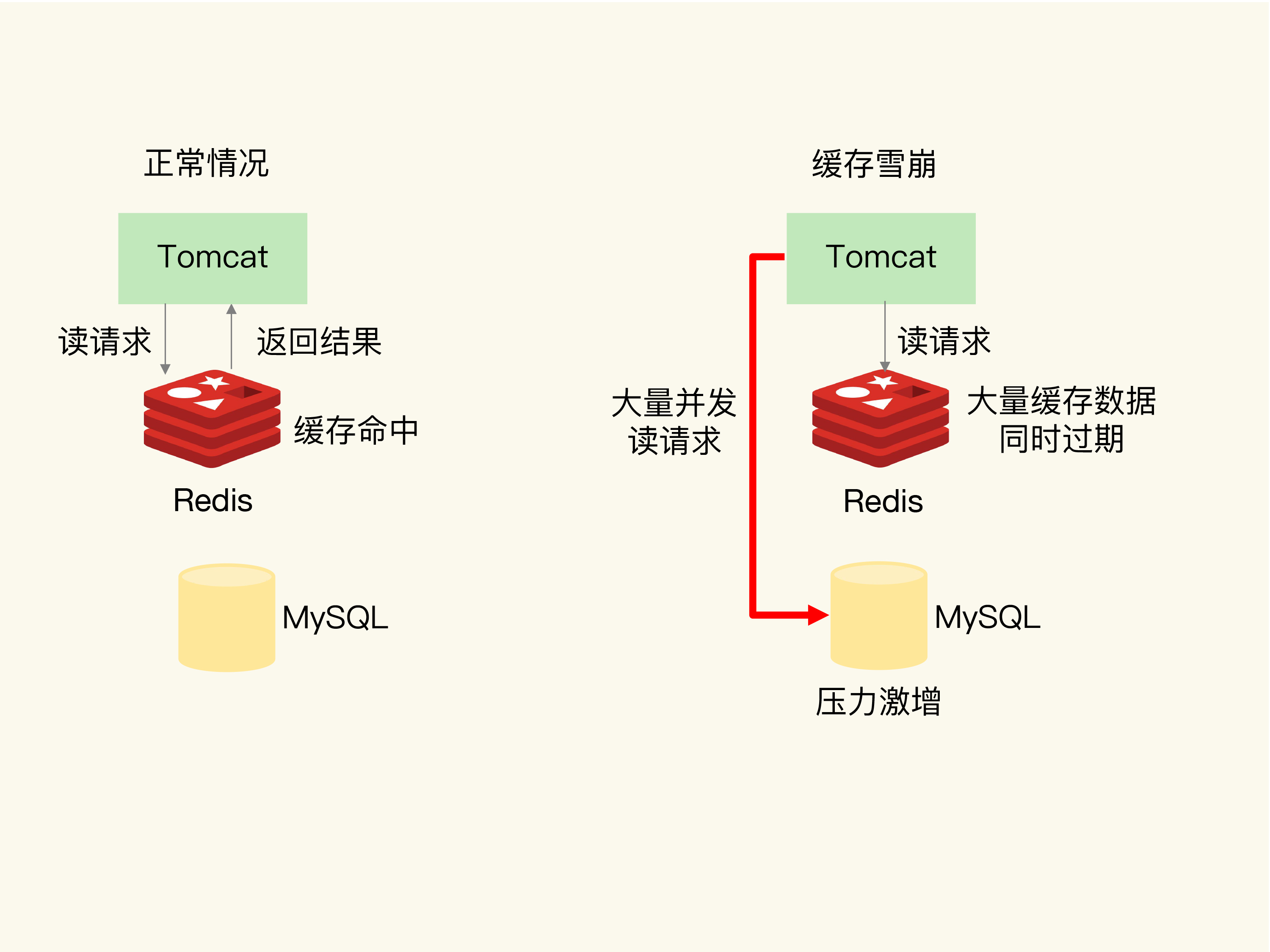
2.缓存雪崩
2.1.概念:
大量的请求无法在缓存中进行处理,进而请求向数据库,导致数据库压力激增
2.2.发生场景及解决措施
-
第一种场景:缓存中大量数据同时失效,导致大量请求无法处理直接请求数据库
解决措施:
(1)过期时间设置一个浮动值,当然这是得在业务场景运行的情况下
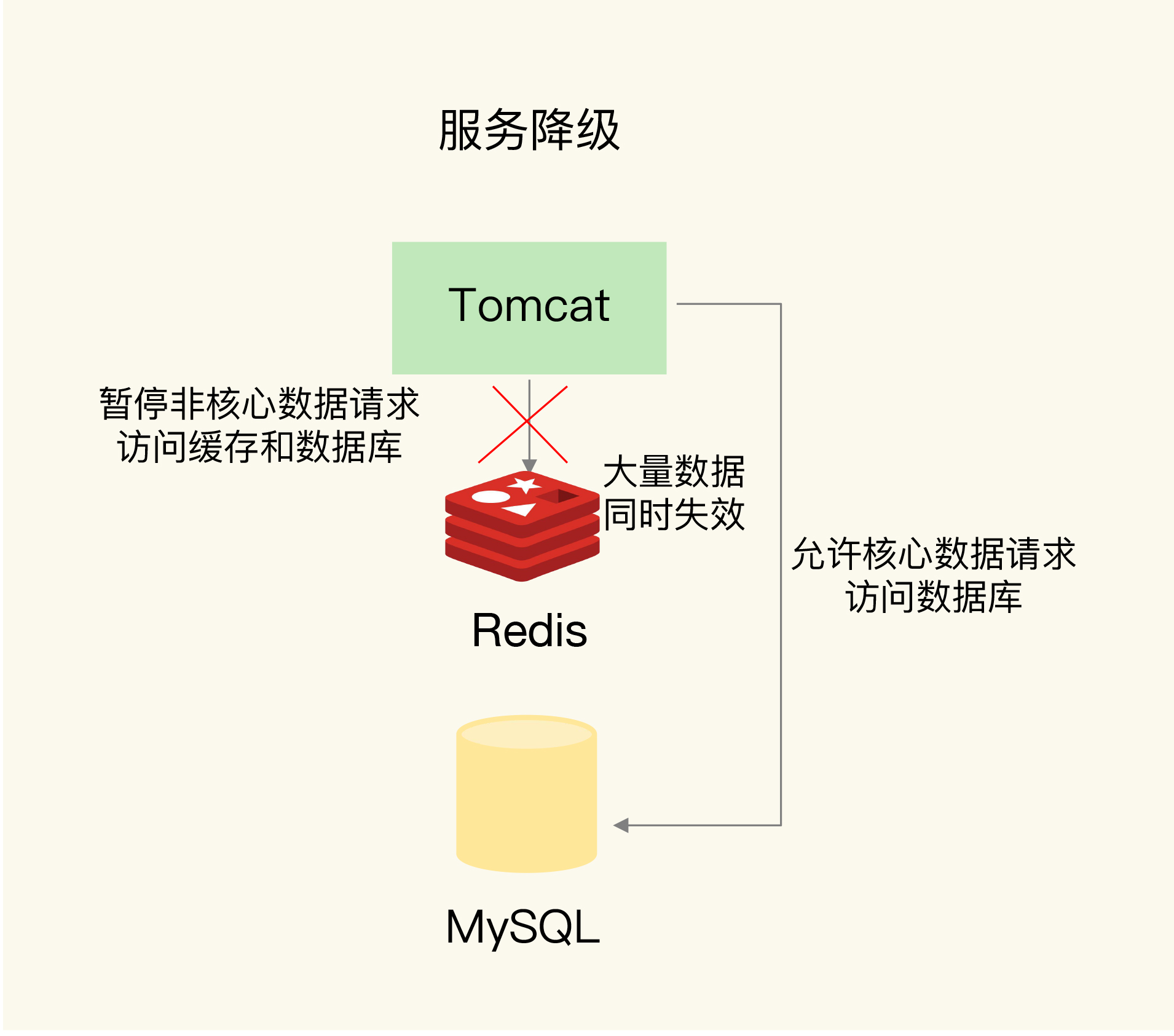
(2)服务降级:服务降级是指针对不同类型的数据采取不同的处理方式,针对请求?。
-
当业务应用访问的是非核心数据(例如电商商品属性)时,暂时停止从缓存中查询这些数据,而是直接返回预定义信息、空值或是错误信息;
-
当业务应用访问的是核心数据(例如电商商品库存)时,仍然允许查询缓存,如果缓存缺失,也可以继续通过数据库读取。
-
第二种场景:redis实例发生宕机,无法处理请求,会导致大量请求打向数据库
解决措施:
(1)业务系统中实现服务熔断:就是发生缓存雪崩的时候,为了方式业务系统崩溃,业务系统调用缓存接口时,缓存客户端发现redis实例宕机了,则拒绝所有的请求并返回直至恢复。虽然这样可以保证数据库的正常运行,但是这样对业务影响比较大。
(2)限流:针对熔断的改进就是限流了,允许少量请求进入,减轻数据库的压力
(3)提前预防:构建redis的高可用集群,方式不可用的风险
3.缓存击穿
3.1.概念
热点数据失效后,针对该热点数据的大量请求打向数据库,与缓存雪崩的区别在于雪崩是大量请求失效,而击穿是热点数据缓存失效。
3.2.解决措施:
1.设置key永不过期
2.数据缺失从数据库同步入缓存的过程上分布式(非阻塞)锁,保证同步过程中只有一个请求去同步,其余请求直接拒绝
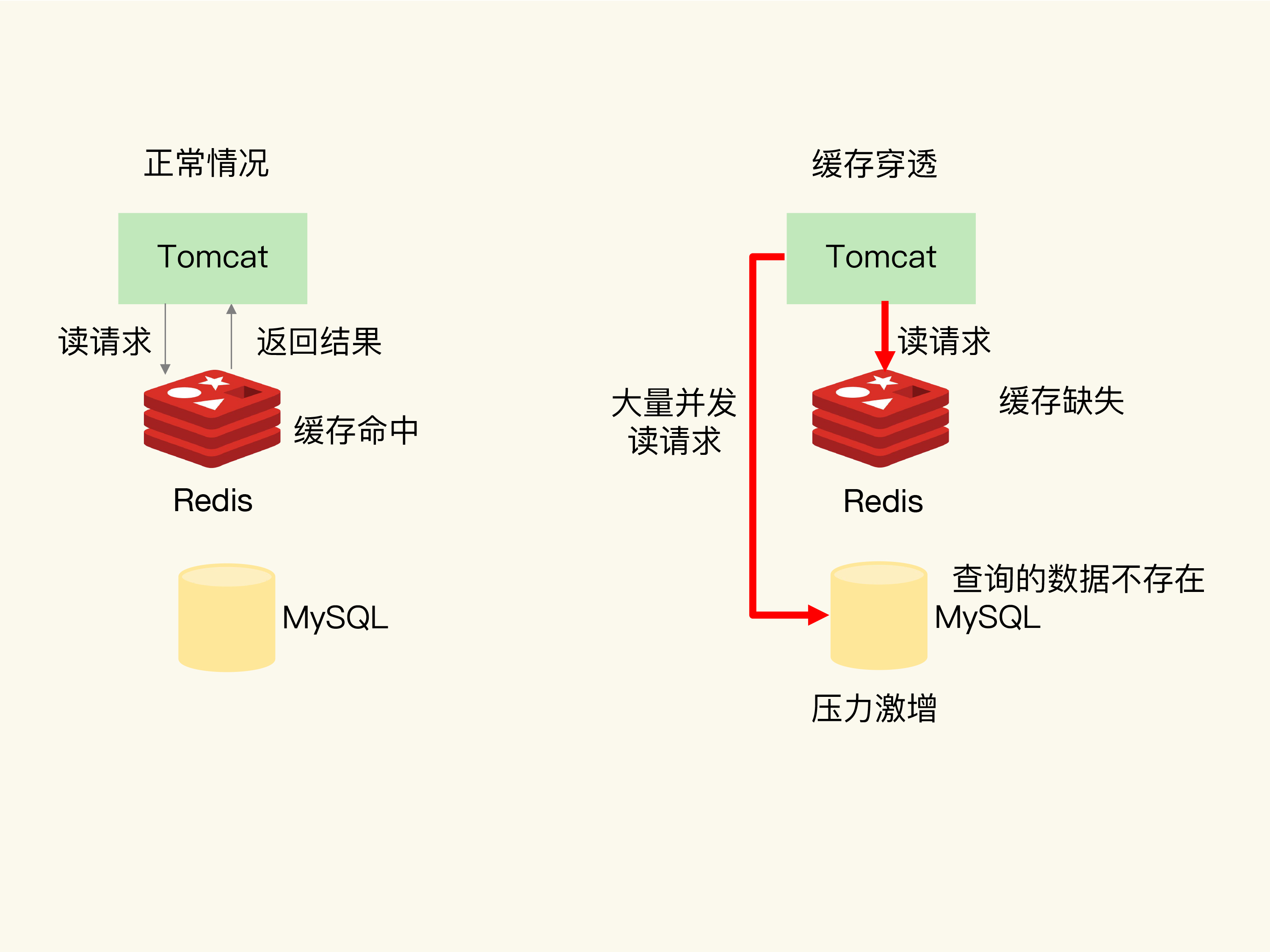
4.缓存穿透
4.1.概念
要访问的数据既不在缓存中也不在数据库中,此时大量请求会同时请求缓存及数据库,这个时候会同时给缓存和数据库带来压力
4.2.解决措施
(1)缓存空值或缺省值:针对数据缺失的数据存储空值或缺省值入redis
(2)前端预防,针对请求进行校验
(3)使用布隆过滤器快速判断数据是否存在,避免从数据库中查询数据是否存在,减轻数据库压力
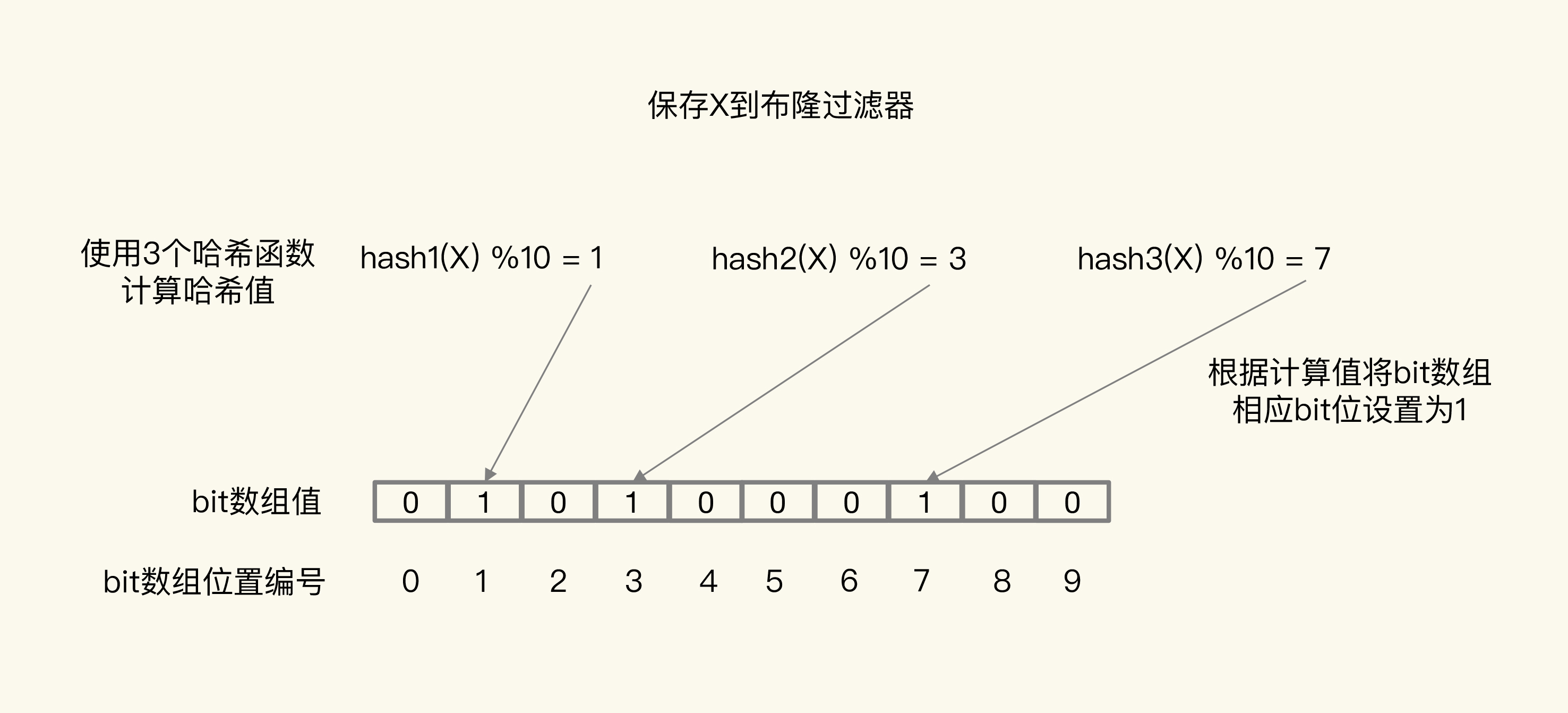
布隆过滤器:
布隆过滤器由一个初始值都为0的bit数组和N个哈希函数组成,用于快速判断数据是否存在。当我们想快速判断数据是否存在是,可以通过判断布隆过滤器的标记进行判断,标记流程如下:
- 数据针对N个哈希函数进行计算得到N个哈希值
- 再将N个哈希值对bit数据的长度取模。将取模后的值对应的下标置为1
如果数据存在,判断时再走一遍标记的流程,查看bit数组中这N个位置上的bit值。只要这N个bit值有一个不为1,这就表明布隆过滤器没有对该数据做过标记,则代表数据不存在,无需查找后端缓存和数据库