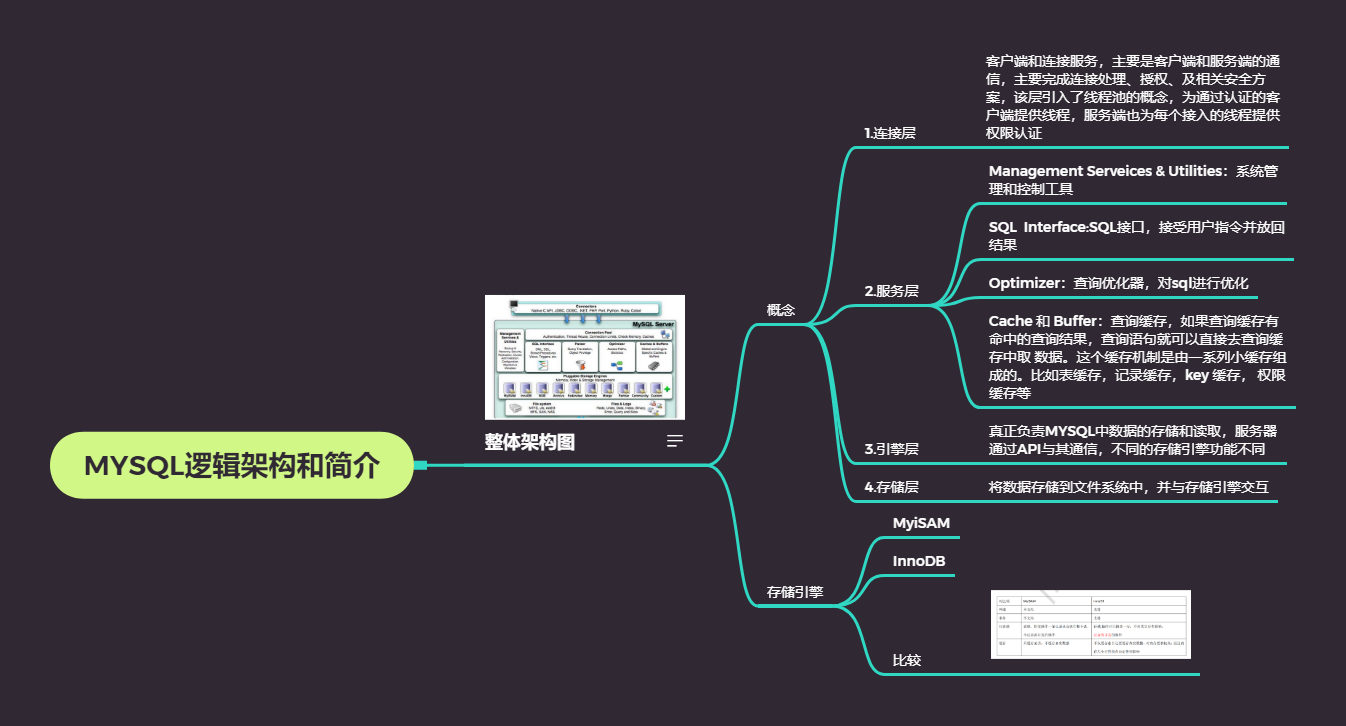
整体架构图
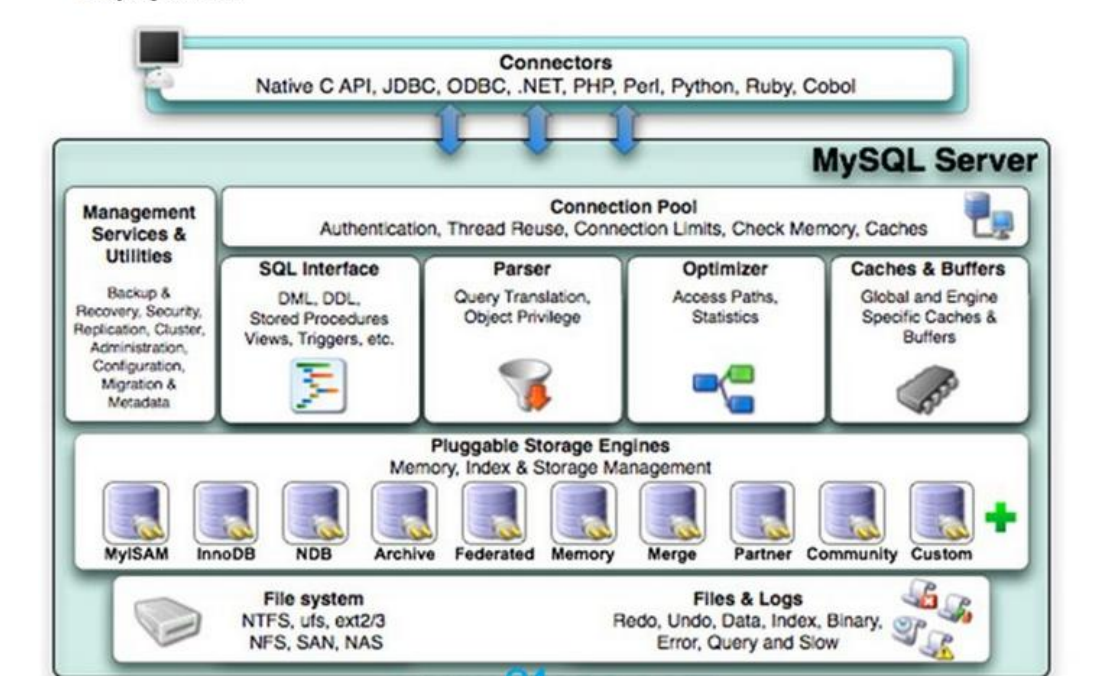
插件式的存储引擎架构将查询处理和其它的系统任务以及数据的存储提取相分离。这种架构可
以根据业务的需求和实际需要选择合适的存储引擎
概念
-
1.连接层
- 客户端和连接服务,主要是客户端和服务端的通信,主要完成连接处理、授权、及相关安全方案,该层引入了线程池的概念,为通过认证的客户端提供线程,服务端也为每个接入的线程提供权限认证
-
2.服务层
- Management Serveices & Utilities:系统管理和控制工具
- SQL Interface:SQL接口,接受用户指令并放回结果
- Optimizer:查询优化器,对sql进行优化
- Cache 和 Buffer:查询缓存,如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取 数据。这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key 缓存, 权限缓存等
-
3.引擎层
- 真正负责MYSQL中数据的存储和读取,服务器通过API与其通信,不同的存储引擎功能不同
-
4.存储层
存储引擎
-
MyiSAM
-
InnoDB
-
1.Buffer Pool
概念:InnoDB维护的一个内存区域,用来缓存数据和索引在内存中,其会将热点数据和认为将要访问到的数据丢到Buffer中,InnoDB在修改数据时,如果数据的页(B+树的一个节点,其中最合适的大小为16K)在Buffer Pool中,则会直接修改Buffer Pool,此时我们称这个页为脏页,InnoDB会以一定的频率将脏页刷新到磁盘中,减少I/O
-
2.InnoDB的四大特性
-
(1)插入缓冲(Insert Buffer)
索引文件是存储在磁盘上的,所以对于索引的操作涉及磁盘I/O,对于部分自增主键的聚簇索引而言,由于连续所以我们插入时候只需要追加就好,不涉及到随机I/O,但是如果涉及到非聚簇索引,如果每次写操作都操作磁盘,将会由于随机读写I/O导致很缓慢(Kafka官方做过测试,顺序I/O的性能大约是随机I/O的4000-5000倍)
因此,InnoDB针对非聚簇索引的更新或插入操作,不是每一次都插入到索引页中,而是如果Buffer Pool中存在该索引页,则先更新Buffer Pool,再以一定的频率和情况进行Insert Buffer 和辅助索引页子节点的 merge(合并)操作,这个时候通常能将多个插入合并到一个操作中(因为在一个索引页中),减少磁盘的随机I/O。
插入缓冲需要满足(1)非聚簇索引(2)索引不是唯一(因为不会去找索引页判断索引唯一,如果判断了就需要去查找,这样又会出现随机读取)
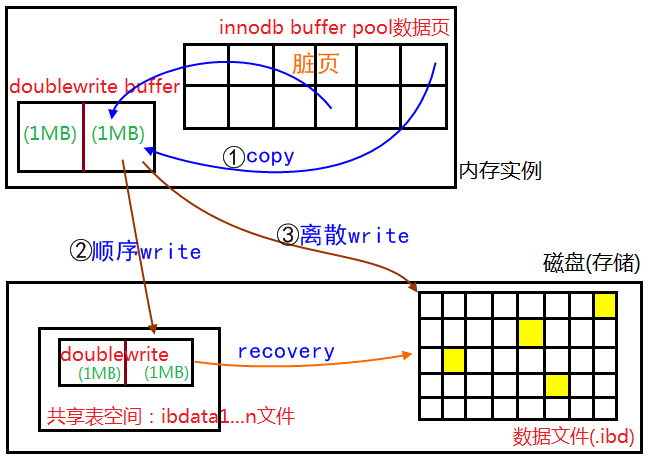
(2)二次写(double write)
脏页刷盘风险:一般InnoDB的pageSize为16KB,而操作系统读写文件是以4KB作为单位,因此脏页存入磁盘需要四个块,于是可能出现16K的数据写入4K时,发生了系统断电或系统崩溃,此时只有部分数据是写成功了,部分数据丢失导致了数据不一致,这就是部分写入问题
并且这个时候无法通过redo.log恢复,redo.log记录的是对页的物理修改,如果页本身已损坏,此时redo.log也无法恢复
此时有了double writer机制
概念:double writer由两部分组成,一部分为内存中的 doublewrite buffer,其大小为2MB,另一部分是磁盘上共享表空间中连续的128个页,即2个区(extent),大小也是2M
为了解决部分写入问题,doublewrite:
(1)先将数据复制到内存中的doublewrite
(2)之后再分两次,将doublewrite中的数据写入到共享表空间的磁盘上(顺序写,很快)
(3)完成第二步之后,马上fsync函数,将doublewriter中的脏页数据写入实际的表文件空间
如果操作系统发生崩溃,InnoDB启动时发现了page损坏,可以通过共享表空间关于该页的最近的一个副本进行数据恢复
(3)自适应哈希索引(adaptive hash index)
由于hash查找的时间复杂度为O(1),但是也存在部分缺点
因此InnoDB会监控对索引表上的查找,如果观察到某些索引被频繁访问,索引成为热数据,这是建立哈希索引会带来性能上的提升。适应哈希索引通过缓冲池的 B+ 树构造而来,因此建立的速度很快。而且不需要将整个表都建哈希索引,InnoDB 会自动根据访问的频率和模式来为某些页建立哈希索引。
(4)预读(read ahead):
InnoDB在I/O上有个比较重要的优化就是预读。当InnoDB认为有page可能将要被查询时,就会异步的将这些数据提前读取到缓冲池(Buffer Pool),
InnoDB使用两种预读算法来提高I/O性能:线性预读(linear read-ahead)和随机预读(randomread-ahead)。
以一个块extent为单位(1块=64page)
线性预读:线性预读中有一个重要的变量:innodb_read_ahead_threshold(可设置为0-64),这个值代表当一个块extent中有超过这个阈值的page被读取,则当前extent的下一个extent将会被读到buffer pool
随机预读:当同一个 extent 中的一些 page 在 buffer pool 中发现时,Innodb 会将该 extent 中的剩余 page 一并读到 buffer pool中。该方式存在不确定性,5.5中已废弃
-
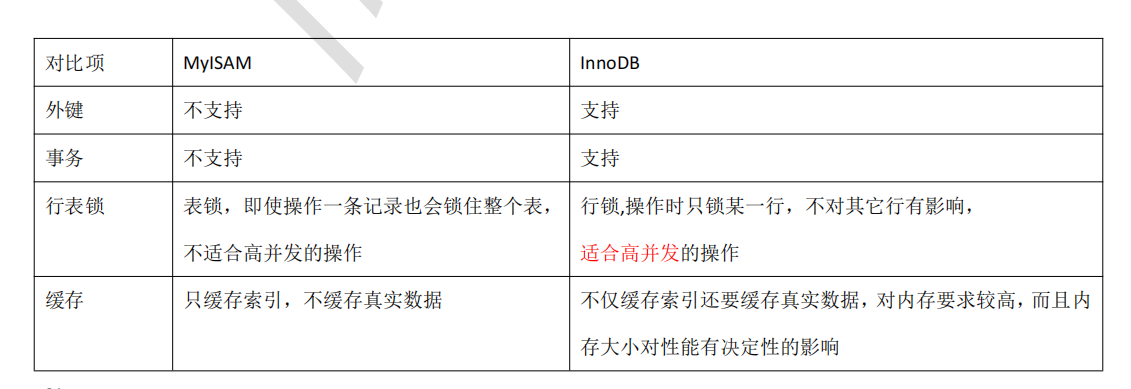
比较
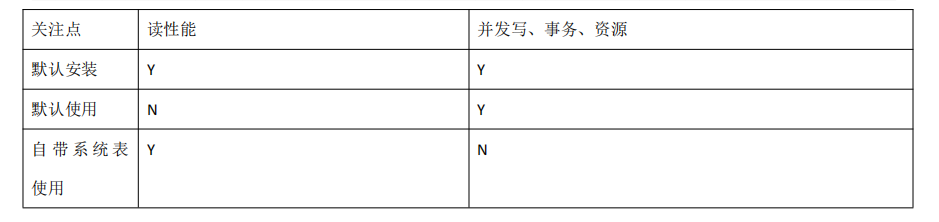
思维导图