常见场景
性能下降SQL慢
产生可能原因
- 查询语句不规范
- 索引失效
- 关联查询太多join
- 服务器调优及各个参数的设置(缓冲,线程数等)
SQL解析
解析顺序
连接
常见的Join查询

索引
是什么
- 排好序的快速查找的数据结构,用于查找和排序
- 一般索引本身都很大,不可能全部都存到内存中,所以所有往往都存储在索引文件中
优势
- 提高检索数据的速度,减少io的成本
- 通过索引列对数据排序,减少排序成本,降低cpu的消耗
劣势
对所有的字段都建立索引是否合适?
- 实际上索引也是一张表,这个表保存了主键和索引列,并指向实体表的记录,所有索引列也需要占用空间
- 加快了读的速度,但是在写的场景下,需要同步维护索引文件添加了索引列的字段
分类
索引结构
- BTree索引
- Hash索引
- full-Text全文索引
- R-Tree索引
为什么MySQL要用B+树作为索引呢?
hash索引:如果只查找单个值,其效率会非常高,但是hash索引有几个问题:(1)不支持排序(2)不支持范围查询(3)不支持最左匹配原则
B树索引:B树的非叶子节点存放了数据记录的地址,会导致存放的节点更少,树的层数变高,范围查找是需要做局部的中序遍历(B+树的叶子节点就是存放的记录本身,并且是一个有序的链表)
红黑树:作为二叉树,层数高,涉及到磁盘操作是,每次向下查找就会涉及一次I/O,效率不高
如何建立呢?
-
需要建立
- 1.主键自动建立唯一索引
- 2.频繁作为查询条件
- 3.查询中与其他表关联的字段,外键
- 4.查询总统计或分组的对象
- 5.字段中的排序字段
-
不需要建立
-
1.表记录太少(300W+就需要考虑了)
-
2.经常增删改
-
3.数据重复且分布平均
-
4.where条件中用不到的字段
-
5.频繁更新的字段
性能分析
索引调优
-
join场景优化
- 1.尽可能减少语句nestedloop的循环总次数,永远用小结果集驱动大结果集
- 2.优先保证NestedLoop的内层循环
- 3.保证join语句中被驱动表上join条件字段已被索引
-
避免索引失效
-
1.全值匹配
-
2.最佳左前缀法则
-
如果索引了多列(复合索引),实际上创了多个索引,例如索引(a,b,c),实际创建了(a),(a,b),(a,b,c)三个索引,所以如果想使用该复合索引,则需要在where中同时使用三个字段检索,或前两个,不能跳着用,带头大哥不能丢
-
组合索引底层还是采取的B+树,并且还是只有一棵树,只是树中节点的排序是先按照第一个排序,在第一个元素相同的情况下再看第二个元素,依次类推,因此才有了最左前缀匹配,如果跳过第一个元素,直接去通过第二三个元素过滤是无法做到的
-
3.不在索引列上做任何操作(函数、计算、转变类型),会导致索引失效
-
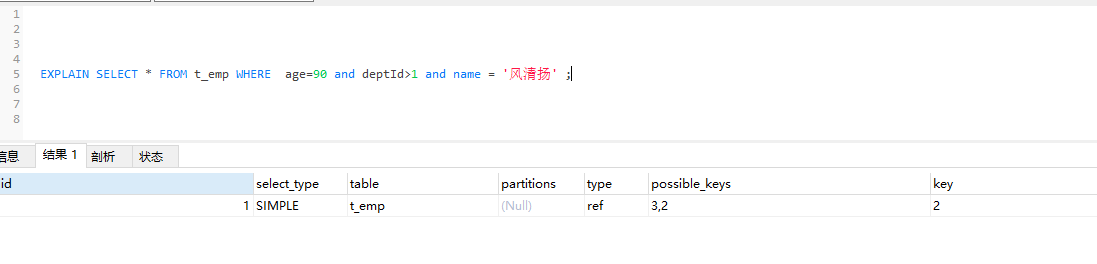
4.存储引擎不能使用范围条件右边的列,这是指复合索引条件下,例如检索a,b,c;但是b使用了范围条件,这个时候就只能使用range,且key_len显示只包括了(a,b),而不是(a,b,b),但是当还存在一个单值索引(c),这个时候type会变成ref,且使用的索引为(c),而不是那个复合索引

-
5.尽量使用复合索引
-
6.使用!=或<>会无法使用索引,导致全表扫描
-
7.is null或者is not null 也无法使用索引
-
8.like以通配符开头(%xxxx)会导致索引失效,导致全表扫描
-
9.字符串不加单引号,索引失效
-
10.少用or,用它连接会导致索引失效
-
针对order by和group by的特殊处理
-
一般性建议
- 1.对于单键索引,尽量选择针对当前query性能更好的索引
- 2.组合索引,过滤性能越好越靠前
- 3.尽可能通过分析信息和调整query的写法来达到选择合适索引的目的
- 4.选择组合索引是,应选择包括当前where条件更多的组合索引
查询优化
1.永远小表驱动大表(类似嵌套循环NestedLoop)
-
exist与in

-
结论:
- exist适合 子查询中表数据大于外查询表中数据的业务场景
- in:适合外部表数据大于子查询的表数据的业务场景
- 原理:exist相当于先执行一次外部select,再拿结果去exist中的条件匹配,说明外部数据量越大,内部匹配的循环次数越多,导致性能更差,in想到与先执行一次子查询的查找,再去拿结果去循环匹配外部的查询,所以子查询所涉及的表越小越好,其中exist中的select是个常量即可,因为mysql会忽略select条件
2.order by关键字优化
-
(1)尽量使用index(扫描有序索引排序)方式排序,避免使用filesort(文件排序)
- order by语句使用组合索引
- 使用where 子句和order by字句条件列组合满足最左前缀匹配
-
(2)尽可能在索引列上完成排序操作,遵照索引建的最左前缀
-
(3)如果不在索引列上,filesort有两种算法,双路排序,单路排序
-
(4)优化策略
- 增大sort_buffer_size的值
- 增大max_length_for_sort_data参数的设置
- 不使用select *
3.group by关键字优化
- group by实际是先排序后分组
- where高于having,能写在where限定条件就不要去having限定
思維导图: