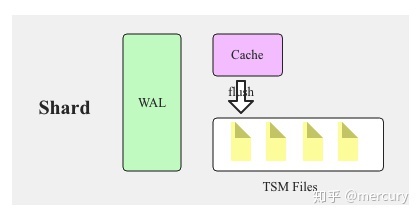
LSM:InfluxDB采用LSM结构,数据先写入内存以及WAL,当内存容量达到一定阈值之后flush成文件,文件数超过一定阈值执行合并
这个过程与其余LSM系统大同小异(例如HBase),不过,InfluxDB在LSM体系架构的基础上针对时序数据做了针对性的存储改进,官方称改进后的存储引擎为TSM(Time-Structured Merge Tree)结构引擎
那么,TSM引擎中文件格式针对时序数据做了哪些针对性的改进,才使得InfluxDB在处理时序数据存储,读写方面表现优异
1.TSM引擎核心基石:时间线
InfluxDB在时序数据模型设计方面提出了一个非常重要的概念:SeriesKey
SeriesKey实际上就是measurment+datasource(tags),时序数据写入内存之后按照SeriesKey进行组织
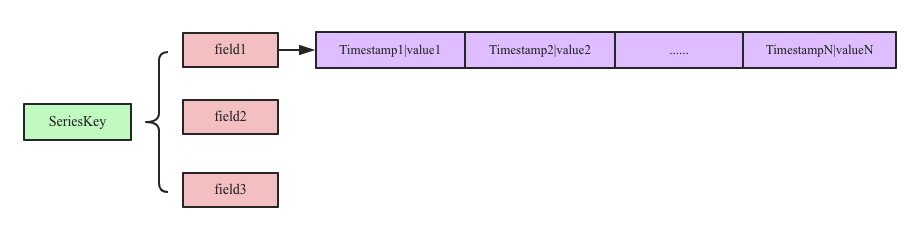
我们认为SeriesKey作为一个数据源的存在,只要数据源存在,数据就会一直产生:
举个例子,SeriesKey相当于是一个智能手环这种东西,智能手环能够有多个采集器,每个采集器其实就是field(metric),但是如果要唯一标识一个智能手环,则需要标签来刻画,因此measurement+tags可以唯一表示一个独一无二的智能手环(其实就是measument下的tag的排列组合成的tags)
2.TSM引擎工作原理-时序数据写入
InfluxDB在内存中使用一个Map来存储时间线数据,这个Map可以表示为<Key, List<Timestamp|Value>>,其中:
Key:seriesKey+fieldKey,Map中一个Key对应一个List,List中存储时间线数据,时序数据写入内存流程可以表示为如下三步:
- 时间序列数据进入系统之后首先根据measurement + datasource(tags)拼成seriesKey
- 再在Map中根据Key找到对应的时间序列集合,如果没有的话就新建一个新的List
- 找到之后将Timestamp|Value组合值追加写入时间线数据链表中
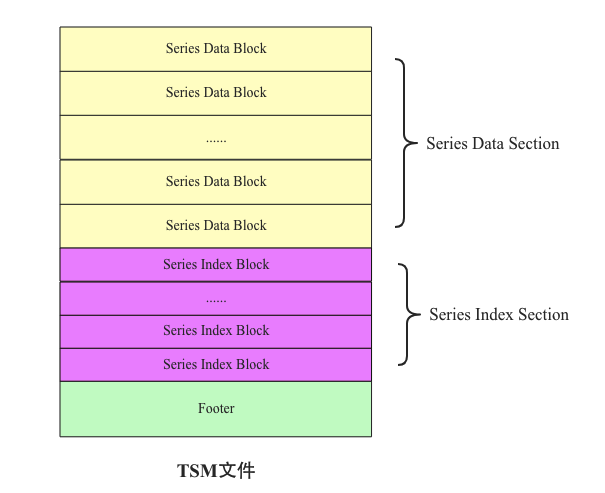
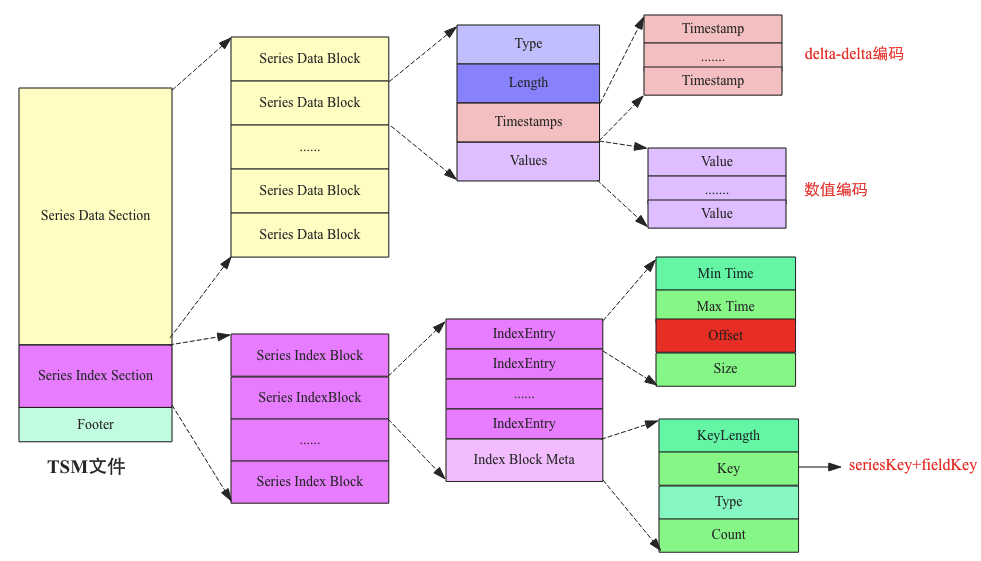
3.TSM文件结构
每隔一段时间,时序数据就会执行flush操作将数据写入到文件(称为TSM文件),整个文件的组织和HBase中HFile基本相同,相同点主要在于两个方面:
- 数据都是以Block为最小读取单元存储在文件中
- 文件数据块都有相应的类B+树索引,而且数据块和索引结构存储在同一个文件中
3.1.Series Data Section
存储时序数据的Block
磁盘块:磁盘进行读写的最小单位,磁盘块一般为512字节
Block(数据块):分布式存储系统中的基本存储单位,一般远大于磁盘块的大小,例如,HDFS block size默认为64MB
分布式存储系统中选择大block size的主要原因是为了最小化寻址开销,使得磁盘传输数据的时间可以明显大于定位这个块所需的时间,block size也不好设置的过大,这是因为MapReduce中的map任务通常一次处理一个块中的数据,因此如果block太大,则map数就会减少,作业运行的并行度就会受到影响,速度就会较慢
Map中一个Key对应一系列时序数据,将同一个Key对应的数据构建成多个连续的Block然后flush到文件中,同一个Block中只会存储同一种Key的数据,但是一个Key的数据可能存储在多个Block中,由于构建索引的需求,Map会按照Key顺序排列并执行flush
Series Data Block文件结构:
这里我们一定要明白:Shard是InfluxDB中提供存储和读写服务的基本单位(可以理解为一个分片),数据point先通过InfluxDB的组织形式落入Shard上,再有的后续内存中的Map,才有了flush刷盘的TSM文件,一个seriesKey其实就代表一个时间轴
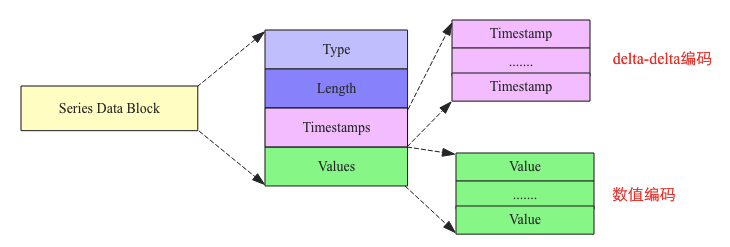
Series Data Block由四部分构成:Type、Length、Timestamps以及Values:
-
Type:表示该SeriesKey对应时间序列的数据类型(field的类型),数值类型通常为int、long、float以及double等。不同数据类型对应不同编码方式
-
Length:len(Timestamps),用于读取Timestamps区域数据,解析Block
时序数据的时间值以及指标值在Block内部是按照列式存储的:所有时间值存储在一起,所有指标值存储在一起,可以提高系统的压缩效率,如上图的Values
-
Timestamps:时间值存储再一起的数据集。时间序列中时间值的间隔都是比较固定的,比如每隔一秒钟采集一次的时间值间隔都是1s,这种具有固定间隔值的时间序列压缩非常高效,TSM采用了Facebook开源的Geringei系统中对时序时间的压缩算法:delta-delta编码
-
Values:指标值存储在一起形成的数据集,同一种Key对应的指标数据的类型相同,相同类型的数据值可以很好的压缩,而且时序数据的特点决定了这些相邻时间序列的数据值基本都相差不大,因此也可以非常高效的压缩。需要注意的是,不同数据类型对应不同的编码算法
3.2.Series Index Block
如果在没有建立索引的情况下,需要查询数据需要将所有的TSM文件加载入内存,然后一个Block一个Block的查找。为了节约内存并提高查询效率,TSM文件引入了索引,其由一系列的索引Block组成,每个Block的结构如下:
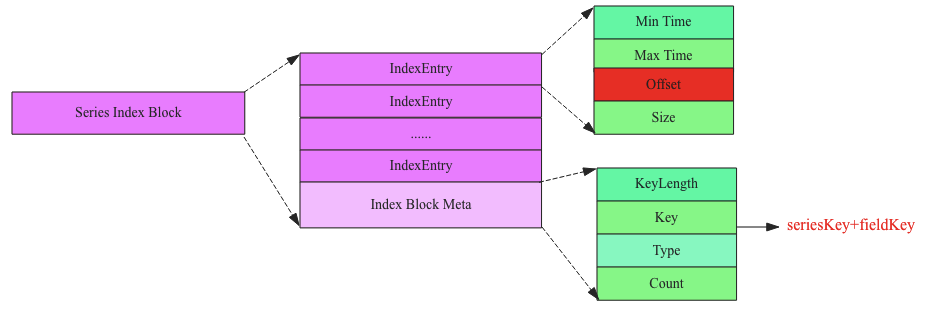
Series Index Block由Index Block Meta和IndexEntry组成:
- Index Block Meta:最核心的字段是Key,用来表示这个索引Block中的所有IndexEntry所索引的时序数据块都是该Key对应的数据
- IndexEntry:表示一个索引字段,指向对应的Series Data Block。指向的Data Block由offset(代表该Block在文件中的偏移量)唯一确定,Size表示指向的Data Block的大小,Min Time和Max Time表示指向的Data Block中时序数据集合的最小时间以及最大时间,用户根据时间范围查找时可以根据这两个字段进行过滤(一个Block中只会存储一种Key)
通过Key我们就能够很快的知道该Series Index Block所索引的Key是哪个
TSM文件总体结构:
4.TSM引擎工作原理-时序数据读取
在一个TSM文件内部的查询过程如下:

图中中间部分是索引层,TSM在启动后会将TSM文件中将索引加载到内存中,数据由于数据量太大,不会加载,具体查询分如下三步:
- 首先根据Key定位到Series Index Block,因为Key都是有序的,可以根据二分查找很快定位
- 查找到SeriesIndex Block再根据查找范围定位到可能的Series Data Block
- 将满足条件的Series Data Block加载到内存中解压进一步使用二分查找算法即可
总结:
所以这里也需要知道为什么InfluxDB或者HBase都不适合存储轩辕的埋点数据了,因为轩辕你的埋点数据每个point中的每个field都是具有相关性的列,就是说我查了A字段,那么我就必须要查出A字段想关联的point的B字段,但是point在时序数据库中可能分布于不同的SeriesKey,也就是可能会落到不同的TSM文件上,所以不适合,那为什么ES适合呢?