1.1.LSM
数据库本质上进行的就是四个操作:1. 插入数据, 2. 删除数据, 3. 修改数据 , 4. 查询数据,也就是我们常说的增删改查,
市面上流行的数据库大致上分为两种:
-
基于日志结构的存储引擎,例如大部分的NoSQL数据库(Redis的AOF日志、Zookeeper的事务日志)
-
面向页的存储引擎,例如MySQL
接下来我们以一个小型日志型数据库的角度出发,来看看其需要具备哪些特性:
第一阶段:极其简单的key-value型数据库
对于插入数据与查询数据我们只需要将数据追加到文件后面即可,对于删除,只需要在key,value后追加一个删除标记即可
那么对于这个简单的KV数据库会有什么问题呢?
- 空间上:修改key对应的值时,采用的是追加写入文件的方式,磁盘早晚会被写满,也会造成拥有许多重复的键
- 时间上:读数据需要遍历一遍文件,数据量大时查询会非常的慢
第二阶段:hashmap索引的分段式数据库
空间耗尽问题的解决:将日志分解为一定大小的段(文件),为每个文件设定一个固定大小的阈值,超过后则关闭当前文件,写入新的文件,仍然是追加写,不过后台会开启一个线程,定时对文件进行合并(AOF重写),每个key上只保留最新的value,如果最新的key,value 上发现了墓碑标记, 则删除该标记。
检索时间过长问题解决:
- 内存中建立hash结构的索引,hash表的key存储数据的key,hash表的值存储记录(value)在文件中的偏移量
- 每个段文件都维持自己的hash表
- 检索流程:按照数据的先后检索hash表,直至数据存在
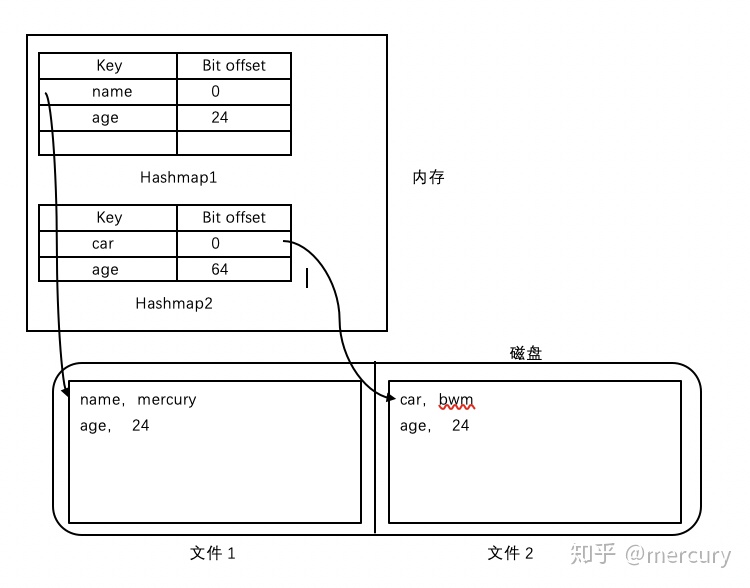
至此我们的实现方式可以总结为: 追加写 + 分段合并 + 分段hash索引 + 标记删除
SSTable 和 LSM-Tree:
SSTable 全称叫做排序字符串表,对于上面的解决方案还有个问题,就是文件中每个段的key我们如果都存储在内存中的话,虽然每个段可以进行压缩,但是占用空间还是太大了
解决方案: 我们可以简单的改变文件的格式, 要求key - value 对的顺序按键进行排序。(前提条件是每个键在每个段文件中只出现一次)
SSTable 的优势:
- 因为键已经基本有序,因此段合并会非常快,因为相同key的记录都在一个段或相邻的段中
- 内存中无需保存所有的key,内存索引可以稍微稀疏(类似于跳表)。比如 有三个键, handwork , handbag 和 handsome , 内存中可以只保存两个键 handbag 和 handsome , 搜索的时候先跳到handbag , 然后开始扫描直到找到handwork。
SSTable的实现:
那么如何实现高效的key排序的结构呢?现在已经有了很多成熟的数据结构可以进行数据高效的动态排序, 例如红黑树。 我们可以在内存中进行排序之后再写入数据库。
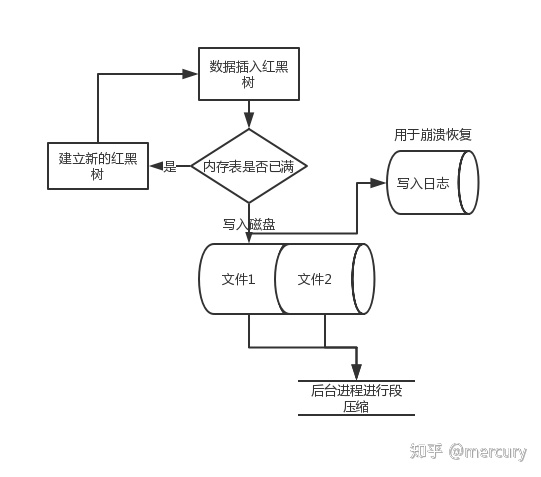
- 写入到内存中的平衡二叉树中(内存表)
- 当内存表大于某个阈值, 将其写入磁盘并创建新的sstable。
- 查找的时候先查找内存, 然后查找最新的磁盘段文件, 然后次新, 直到找到目标。
- 后台周期型的执行段合并和压缩(多路归并)。
- 写入日志预防崩溃。
上面所描述的算法流程正式levelDB 和RocksDB 所使用的。 它的名字叫做日志结构合并树(LSM-Tree)。
在它落地的过程中, 还有一些细节进行了输入的优化。
例如: 查找每个不存在的键, LSM-Tree 会变得很慢。 优化方案: 布隆过滤器。
关于SStables 的压缩和合并式的具体顺序和时机。 各个存储引擎也有所不同, 常见的有分层压缩(LevelDB) 和大小分级(HBase)。
LSM-Tree 基本思想:
key 按字典序排序, 稀疏存储,使数据集可以远大于可用内存。