1. HBase是什么
是一个分布式的、面向列存储的 NoSQL数据库,基于 Google 的 Bigtable 设计,用于处理海量的结构化数据。HBase 架构的独特性使其在大数据领域得到了广泛应用,主要用来存储非结构化和半结构化的松散数据
HBase 最早由 Apache Hadoop 的开发者开发,用于解决在 Hadoop 分布式文件系统(HDFS)上存储和检索大量数据时面临的挑战。传统的关系型数据库在处理大规模数据时效率低下,难以扩展。而 HBase 作为一个 NoSQL 数据库,提供了对大量数据的高效读写操作,并且具有高度的扩展性。
项目需求是构建一个可以处理数十亿条记录的大规模数据存储系统,要求系统能够承载高并发的读写请求,同时在数据量急剧增长的情况下,系统性能不会显著下降。HBase 的设计正是为此类需求量身定制。
2. HBase数据检索与存储
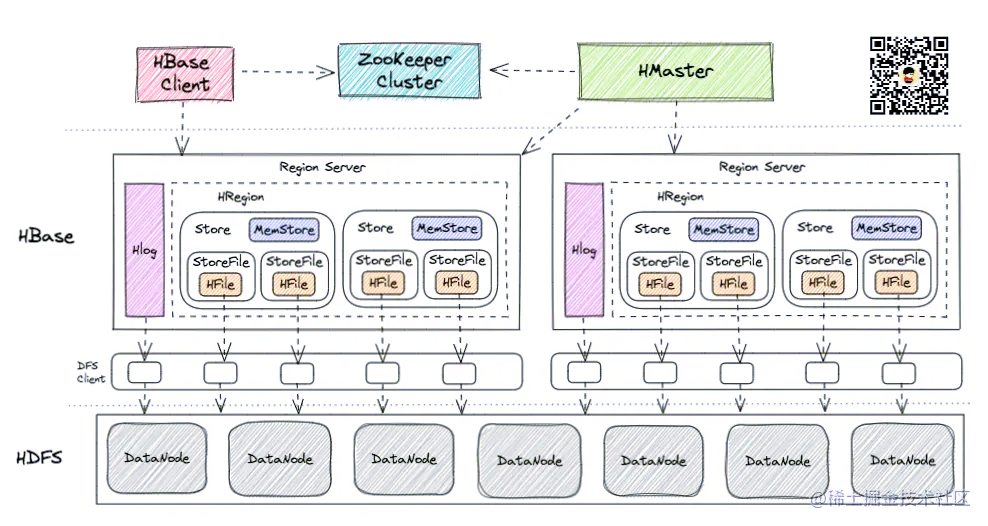
| 模块 | 职责 |
|---|
| HBase Client | HBase Client 为用户提供了访问 HBase 的接口,可以通过元数据表来定位到目标数据的 RegionServer,另外 HBase Client 还维护了对应的 cache 来加速 Hbase 的访问,比如缓存元数据的信息 |
| HMaster | HMaster 是 HBase 集群的主节点,负责整个集群的管理工作,主要工作职责如下分配Region:负责启动的时候分配Region到具体的 RegionServer;负载均衡:一方面负责将用户的数据均衡地分布在各个 Region Server 上,防止Region Server数据倾斜过载。另一方面负责将用户的请求均衡地分布在各个 Region Server 上,防止Region Server 请求过热维护数据:发现失效的 Region,并将失效的 Region 分配到正常的 RegionServer 上,并且在Region Sever 失效的时候,协调对应的HLog进行任务的拆分。 |
Region Server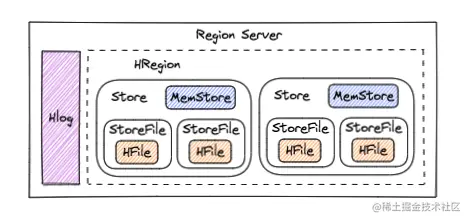 | 直接对接用户的读写请求,干活的节点,每一个Region server大约可以管理1000个region,处理对这些HRegion的IO请求,也就是说客户端直接和HRegionServer打交道,主要职责如下管理 HMaster 为其分配的 Region;负责与底层的 HDFS 交互,存储数据到 HDFS;负责 Region 变大以后的拆分以及 StoreFile 的合并工作。 |
| Region(table) | Region Server 包含多个Region。每一个 Region 都有起始 RowKey 和结束 RowKey,代表了存储的Row的范围,保存着表中某段连续的数据。一开始Region可能只有一个,随着数据增多(StoreFile变大,默认256M),进行Region的水平切分,分成了多个Region。当 Region 很多时,HMaster 会将 Region 保存到其他 Region Server 上 |
| HLog(WAL) | 每个Region Server会有一个HLog,负责记录着数据的操作日志,当HBase出现故障时可以进行日志重放、故障恢复。例如故障时MemStore没有写会磁盘 |
| Store(列蔟) | 一个 Region 包含多个 Store ,每个 Store 都对应一个 Column Family, Store 包含 MemStore 和 StoreFile |
| MemStore(Store的内存存储) | 数据的写操作会先写到 MemStore 中,当MemStore 中的数据增长到一个阈值(默认64M)后。Region Server 会启动 flasheatch 进程将 MemStore 中的数据写人 StoreFile 持久化存储,每次写入后都形成一个单独的 StoreFile。找数据会先从MemStore开始找,找不到才去StoreFile |
| StoreFile(HFile) | StoreFile底层是以 HFile 的格式保存。HBase以Store的大小来判断是否需要切分Region |
| HFile是HBase中KeyValue数据的存储格式,是hadoop的二进制格式文件。一个StoreFile对应着一个HFile。而HFile是存储在HDFS之上的 | |
| Zookeeper | HBase 通过 ZooKeeper 来完成选举 HMaster、监控 Region Server、维护元数据集群配置等工作,主要工作职责如下选举Master:如果 HMaster 异常,则会通过选举机制(写入节点成功的节点作为HMaster)产生新的 HMaster 来提供服务监控Region Server: 通过 ZooKeeper 来监控 Region Server 的状态,当Region Server 有异常的时候,通过回调的形式通知 HMaster 有关Region Server 上下线的信息维护元数据和集群配置信息 |
| HDFS | 为 HBase 提供底层数据存储服务,同时为 HBase提供高可用的支持 |
3. HBase数据模型与操作
3.1. 数据模型
基本存储单位是表(Table),表由行(Row)和列族(Column Family)组成。每个列族可以包含多个列(Column),而列的数据通过时间戳(Timestamp)进行版本控制
| Row Key | Column Family(Cloumn Family):Column(列限定符) | Value | Timestamp |
|---|
| row1 | cf1:col1 | value1 | 1627871234000 |
| row1 | cf1:col2 | value2 | 1627871235000 |
| row2 | cf1:col1 | value3 | 1627871236000 |
| 字段 | 含义 |
|---|
| RowKey | 唯一标识一行记录,由于HBase都是按照rowKey进行region路由,因此针对rowKey的设计需要注意 |
| Column Family | HBase中的每个列都由Cloumn Family(列簇)和Cloumn Qualifier(列限定符)进行限定,例如info:name,info:age。建表时,只需指明列簇,而列限定符无需预先定义 |
| Time Stamp | 用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入HBase的时间 |
Cell
{ RowKey, ColumnFamily: ColumnQualifier, TimeStamp}
唯一确定的单元。cell 中的数据是没有类型的,全部是字节码形式存贮
3.2. 主要操作
HBase 提供了丰富的 API 进行数据操作,包括 Put、Get、Delete 和 Scan。Put 用于写入数据,Get 用于读取数据,Delete 用于删除数据,Scan 用于批量读取数据。
- Put:将数据写入表中。
- Get:根据行键读取数据。
- Delete:删除指定行或列的数据。
- Scan:遍历表中的数据。
3.2.1. 写流程

- 获取meta表信息:客户端先访问zookeeper,获取Meta表位于那个region server,根据根据请求的信息
(namespace:table/rowkey),在meta表中查询出目标数据位于哪个region server的哪个region中,然后缓存在客户端中
- 与目标数据的region server进行通讯
- 将数据写入到WAL中
- 将数据写入到对应的memstore中,
- 向客户端发送写入成功的信息
- 等达到memstore的刷写时机后,将数据刷写到HFILE中
更新操作:并没有真正更新原有数据,而是使用时间戳属性实现了多版本;
删除操作:没有真正删除原有数据,只是插入了一条标记为"deleted"标签的数据,而真正的数据删除发生在系统异步执行Major Compact的时候
3.2.2. 读流程
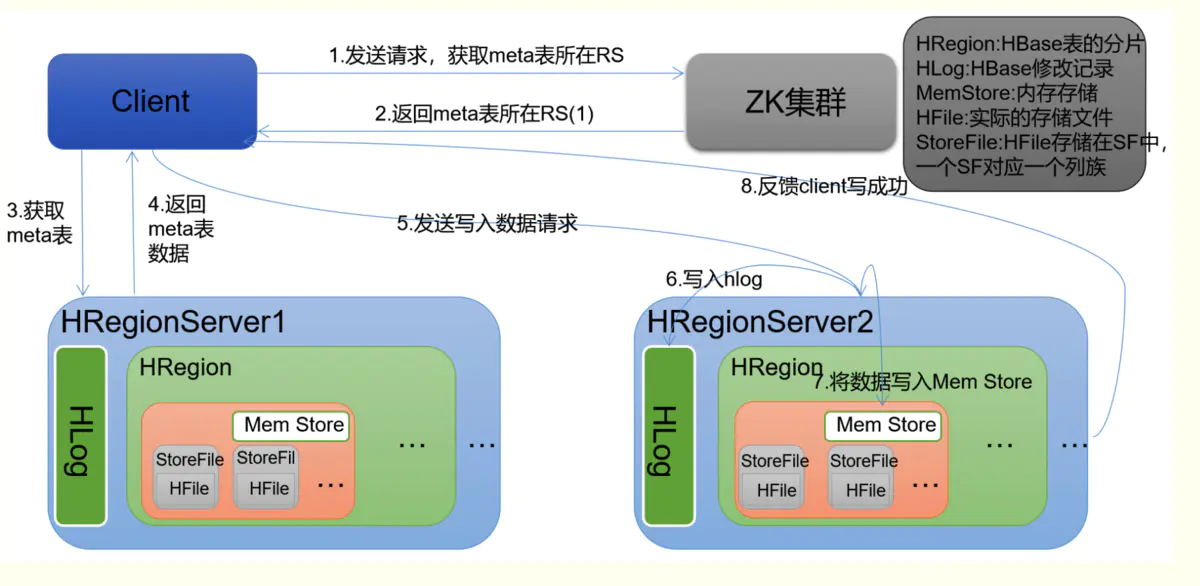
- 获取meta表信息:客户端先访问zookeeper,获取Meta表位于那个region server,根据根据请求的信息
(namespace:table/rowkey),在meta表中查询出目标数据位于哪个region server的哪个region中,然后缓存在客户端中
- 请求对应region server
- 分别在Block Cache(读缓存),MemStore和 Store File查询目标数据,并将查到的数据进行**合并,**此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)
- 将从文件中查询到的数据块缓存到block cache
- 将合并后的数据返回给客户端
API操作主要划分如下:
- GET
- SCAN - 一般HBase会根据设置条件将一次大的scan操作拆分为多个RPC请求,每个RPC请求称为一次next请求,每次只返回规定数量的结果,类似于ES的search-after。每次可以设置setBatch(条数)、setMaxResultSize(数据量大小)
3.2.2.1. Scan查询详细流程
Scan查询大致分为下述四个流程
- Client-Server读取交互逻辑
- HBase的scan框架
- HBase过滤淘汰不符合条件的HFile
- 从HFile中读取待查找Key
3.2.2.1.1. Client-Server读取交互逻辑
Client首先会从ZooKeeper中获取元数据hbase:meta表所在的RegionServer,然后根据待读写rowkey发送请求到元数据所在RegionServer,获取数据所在的目标RegionServer和Region(并将这部分元数据信息缓存到本地),最后将请求进行封装发送到目标RegionServer进行处理。
HBase Client端与Server端的scan操作并没有设计为一次RPC请求,这是因为一次大规模的scan操作很有可能就是一次全表扫描,扫描结果非常之大,通过一次RPC将大量扫描结果返回客户端会带来至少两个非常严重的后果:
•大量数据传输会导致集群网络带宽等系统资源短时间被大量占用,严重影响集群中其他业务。
•客户端很可能因为内存无法缓存这些数据而导致客户端OOM。
实际上HBase会根据设置条件将一次大的scan操作拆分为多个RPC请求,每个RPC请求称为一次next请求,每次只返回规定数量的结果。下面是一段scan的客户端示例代码:
3.2.2.1.2. HBase的scan框架
Scan中,会根据startRowKey、endRowKey查询多个Region server
RegionServer接收到客户端的get/scan请求之后做了两件事情:
- 首先构建scanner iterator体系;
- 然后执行next函数获取KeyValue,并对其进行条件过滤
3.2.2.1.2.1. scanner iterator体系
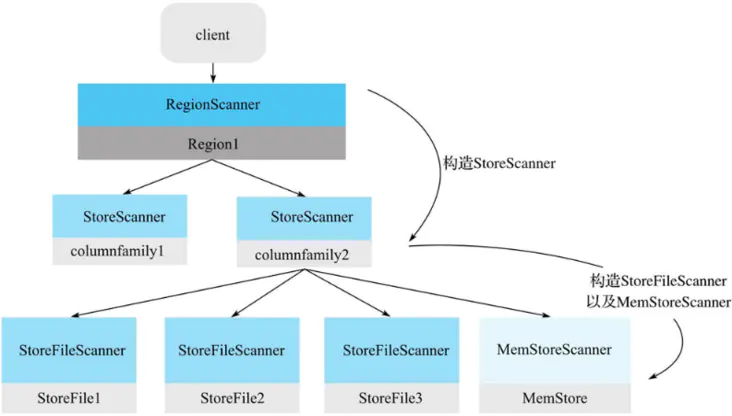
Scanner的核心体系包括三层Scanner:RegionScanner,StoreScanner,MemStoreScanner和StoreFileScanner。三者是层级的关系:
- 一个RegionScanner由多个StoreScanner构成。一张表由多少个列簇组成,就有多少个StoreScanner,每个StoreScanner负责对应Store的数据查找。
- 一个StoreScanner由MemStoreScanner和StoreFileScanner构成。每个Store的数据由内存中的MemStore和磁盘上的StoreFile文件组成。相对应的,StoreScanner会为当前该Store中每个HFile构造一个StoreFileScanner,用于实际执行对应文件的检索。同时,会为对应MemStore构造一个MemStoreScanner,用于执行该Store中MemStore的数据检索。
需要注意的是,RegionScanner以及StoreScanner并不负责实际查找操作,它们更多地承担组织调度任务,负责KeyValue最终查找操作的是StoreFileScanner和MemStoreScanner。三层Scanner体系可以用图表示。
3.2.2.1.3. HBase过滤淘汰不符合条件的HFile
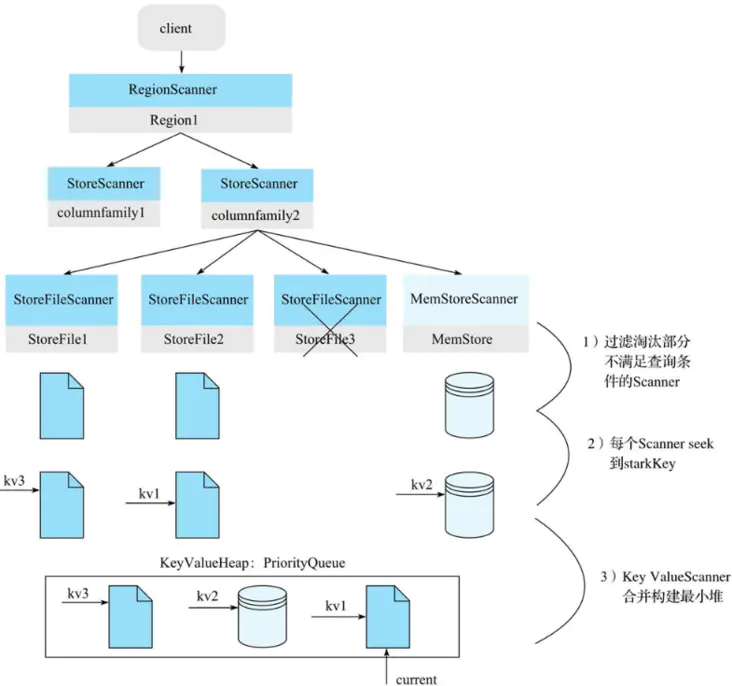
通过不同的scanner进行查找,过滤HFile->根据Key在HFile进行读取数据,最终产出一个keyValue(Cell)的优先队列(小顶堆),next的查询模式就是基于这个优先队列(Key ValueScanner)进行keyValue的查找,并最终从HFile中读取到数据
其中keyValue的优先队列的生成过程如下
-
过滤淘汰部分不满足查询条件的StoreScanner,可以先基于用户查询中的TimeRange,Rowkey Range过滤以及布隆过滤器过滤部份HFile
-
- TimeRange(时序数据):StoreFile中元数据有一个关于该File的TimeRange属性[ miniTimestamp, maxTimestamp ],如果待检索的TimeRange与该文件时间范围没有交集,就可以过滤掉该StoreFile;另外,如果该文件所有数据已经过期,也可以过滤淘汰
- Rowkey Range:因为StoreFile中所有KeyValue数据都是有序排列的,所以如果待检索row范围[ startrow,stoprow ]与文件起始key范围[ f irstkey,lastkey ]没有交集,比如stoprow < firstkey或者startrow > lastkey,就可以过滤掉该StoreFile
- 布隆过滤器:主要根据Bloom Block,待检索的rowkey获取对应的Bloom Block并加载到内存(通常情况下,热点Bloom Block会常驻内存的),再用hash函数对待检索rowkey进行hash,根据hash后的结果在布隆过滤器数据中进行寻址,即可确定待检索rowkey是否一定不存在于该HFile
-
每个Scanner seek到startKey。这个步骤在每个HFile文件中(或MemStore)中seek扫描起始点startKey(下文:从HFile中读取待查找Key)。如果HFile中没有找到starkKey,则seek下一个KeyValue地址,这个过程会比较复杂。
-
KeyValueScanner合并构建最小堆。将该Store中的所有StoreFileScanner和MemStoreScanner合并形成一个heap(最小堆)
-
最后,执行最终读取,例如执行next函数获取KeyValue并对其进行条件过滤
-
- 检查该KeyValue的KeyType是否是Deleted/DeletedColumn/DeleteFamily等,如果是,则直接忽略该列所有其他版本,跳到下列(列簇)。
- 检查该KeyValue的Timestamp是否在用户设定的Timestamp Range范围,如果不在该范围,忽略。
- 检查该KeyValue是否满足用户设置的各种filter过滤器,如果不满足,忽略。
- 检查该KeyValue是否满足用户查询中设定的版本数,比如用户只查询最新版本,则忽略该列的其他版本;反之,如果用户查询所有版本,则还需要查询该cell的其他版本。
注意,其中一个KeyValue其实就是一个cell = {rowKey,colounm family,timeStamp,value}
3.2.2.1.3.1. 各种Filter过滤器
在HBase里,Scan 的 Filter 支持多种过滤操作,以下为你详细介绍:
\1. 比较过滤器
- SingleColumnValueFilter:此过滤器用于筛选特定列族和列限定符的值,它依据比较运算符和比较器来判定是否保留该行。示例代码如下:
SingleColumnValueFilter filter = new SingleColumnValueFilter(
Bytes.toBytes("cf"),
Bytes.toBytes("column"),
CompareOperator.EQUAL,
new BinaryComparator(Bytes.toBytes("value"))
);
scan.setFilter(filter);
- RowFilter:按照行键对数据进行过滤,同样借助比较运算符和比较器来实现。示例如下:
RowFilter rowFilter = new RowFilter(
CompareOperator.EQUAL,
new BinaryComparator(Bytes.toBytes("rowkey"))
);
scan.setFilter(rowFilter);
- FamilyFilter:用于筛选特定列族的数据,通过比较运算符和比较器达成。示例如下:
FamilyFilter familyFilter = new FamilyFilter(
CompareOperator.EQUAL,
new BinaryComparator(Bytes.toBytes("cf"))
);
scan.setFilter(familyFilter);
- QualifierFilter:该过滤器可筛选特定列限定符的数据,利用比较运算符和比较器完成。示例如下:
QualifierFilter qualifierFilter = new QualifierFilter(
CompareOperator.EQUAL,
new BinaryComparator(Bytes.toBytes("column"))
);
scan.setFilter(qualifierFilter);
\2. 组合过滤器
- FilterList:能够把多个过滤器组合起来使用,支持
MUST_PASS_ALL(所有过滤器都必须通过)和 MUST_PASS_ONE(只要有一个过滤器通过即可)两种组合方式。示例如下:
FilterList filterList = new FilterList(FilterList.Operator.MUST_PASS_ALL);
filterList.addFilter(filter1);
filterList.addFilter(filter2);
scan.setFilter(filterList);
\3. 专用过滤器
- PageFilter:用于实现分页功能,可指定每页返回的行数。示例如下:
PageFilter pageFilter = new PageFilter(10); // 每页返回 10 行
scan.setFilter(pageFilter);
- PrefixFilter:按照行键的前缀进行过滤,只返回行键以指定前缀开头的行。示例如下:
PrefixFilter prefixFilter = new PrefixFilter(Bytes.toBytes("prefix"));
scan.setFilter(prefixFilter);
- ColumnPrefixFilter:根据列限定符的前缀来筛选数据,只返回列限定符以指定前缀开头的列。示例如下:
ColumnPrefixFilter columnPrefixFilter = new ColumnPrefixFilter(Bytes.toBytes("prefix"));
scan.setFilter(columnPrefixFilter);
- FirstKeyOnlyFilter:仅返回每行的第一个键值对,常用于快速统计行数。示例如下:
FirstKeyOnlyFilter firstKeyOnlyFilter = new FirstKeyOnlyFilter();
scan.setFilter(firstKeyOnlyFilter);
这些过滤器能让你在HBase中精准地筛选数据,以满足不同的业务需求。
3.2.2.1.3.2. 其他API
时间处理HBase的Scan操作中是有与时间相关的过滤器的,下面为你详细介绍:
\1. TimestampsFilter
该过滤器允许你指定一系列时间戳,只有当单元格的时间戳与指定的时间戳相匹配时,才会返回该单元格。以下是Java代码示例:
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.TimestampsFilter;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class TimeStampFilterExample {
public static void main(String[] args) throws IOException {
// 创建连接
Connection connection = ConnectionFactory.createConnection();
// 获取表
Table table = connection.getTable(TableName.valueOf("your_table_name"));
// 创建Scan对象
Scan scan = new Scan();
// 指定时间戳列表
List<Long> timestamps = new ArrayList<>();
timestamps.add(1609459200000L);
timestamps.add(1609545600000L);
// 创建TimestampsFilter
TimestampsFilter filter = new TimestampsFilter(timestamps);
scan.setFilter(filter);
// 执行扫描
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
// 处理结果
System.out.println(result);
}
// 关闭资源
scanner.close();
table.close();
connection.close();
}
}
在这个示例中,我们创建了一个**TimestampsFilter**,并指定了两个时间戳。只有时间戳与这两个值相匹配的单元格才会被返回。
\2. 在Scan对象中直接设置时间范围
除了使用过滤器,你还可以在**Scan**对象中直接设置时间范围,只有时间戳在该范围内的单元格才会被返回。示例代码如下:
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class TimeRangeScanExample {
public static void main(String[] args) throws IOException {
// 创建连接
Connection connection = ConnectionFactory.createConnection();
// 获取表
Table table = connection.getTable(TableName.valueOf("your_table_name"));
// 创建Scan对象
Scan scan = new Scan();
// 设置时间范围
long startTime = 1609459200000L;
long endTime = 1609545600000L;
scan.setTimeRange(startTime, endTime);
// 执行扫描
ResultScanner scanner = table.getScanner(scan);
for (Result result : scanner) {
// 处理结果
System.out.println(result);
}
// 关闭资源
scanner.close();
table.close();
connection.close();
}
}
在上述代码里,我们使用**setTimeRange**方法设置了一个时间范围,只有时间戳在这个范围内的单元格才会被返回。
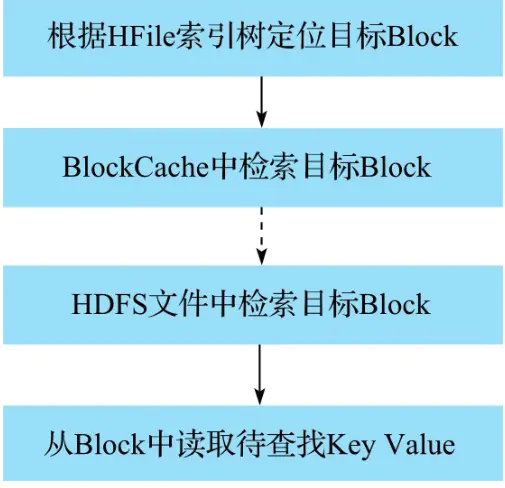
3.2.2.1.4. 从HFile中读取待查找Key
最后根据KevValue去HFIle中查找具体数据,查询流程如下:
3.2.3. MemStore刷写
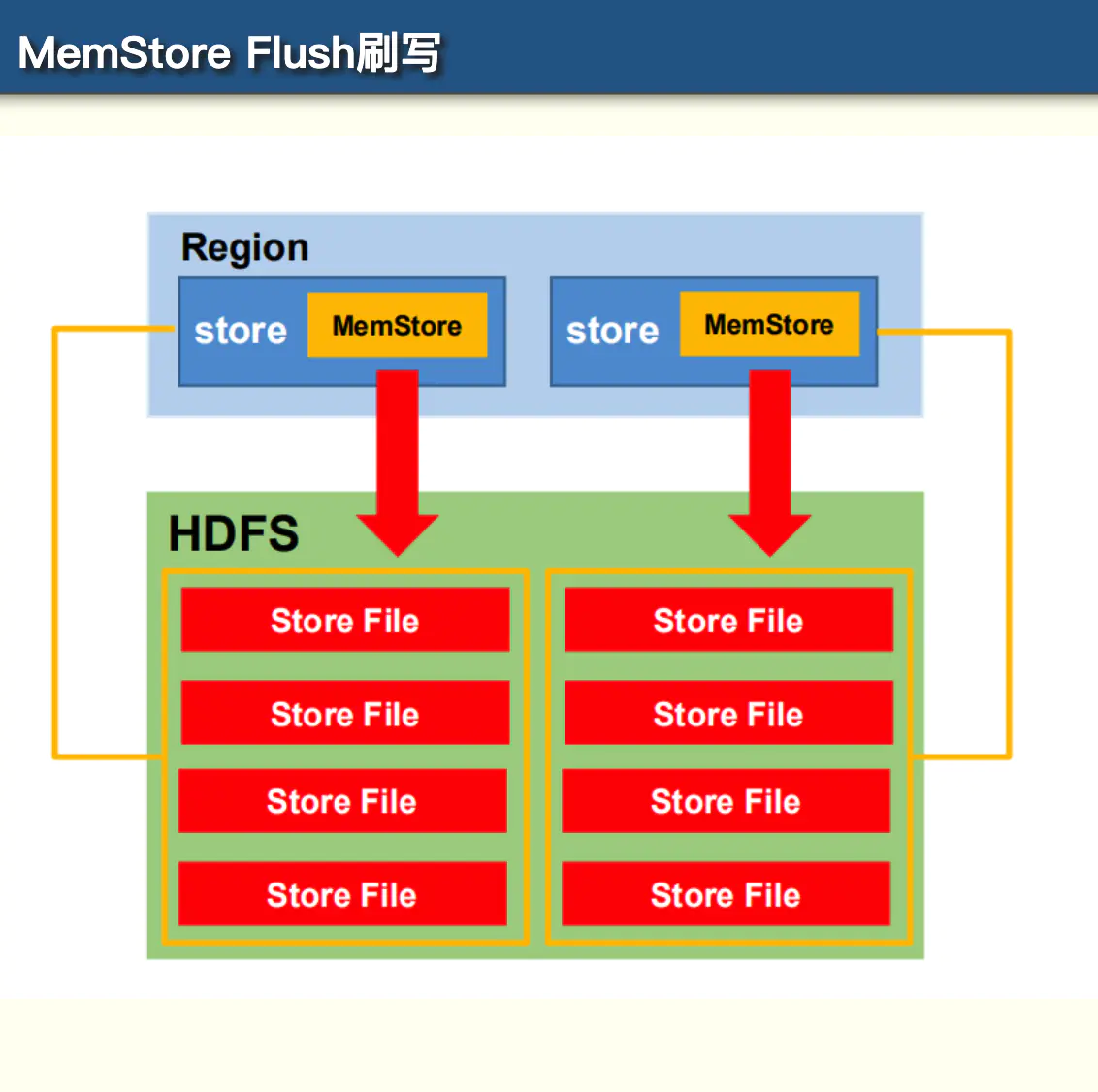
MemStore触发刷写的场景如下:
- 单一MemStore超大小128M:某个MemStore的大小达到了hbase.hregion.memstore.flush.size(默认值 128M),其所在 region 的所有 memstore (对应的列簇)都会刷写,当达到128 * N 还没有刷写,此时会拒绝写入。
两个相关参数的默认值如下:
hbase.hregion.memstore.flush.size=128M(默认)
hbase.hregion.memstore.block.multiplier=4(默认)
- memstore总大小超过堆内存:当 region server 中 memstore 的总大小达到java_heapsize(应用的堆内存)*hbase.regionserver.global.memstore.size时
hbase.regionserver.global.memstore.size=0.4(默认值)
- 定时刷写:到达自动刷写的时间,也会触发 memstore flush,默认时1h
- WAL文件超大:WAL 文件的数量超过 hbase.regionserver.maxlogs,region 会按照时间顺序依次进行刷写
3.2.4. 数据合并(StoreFile Compaction)
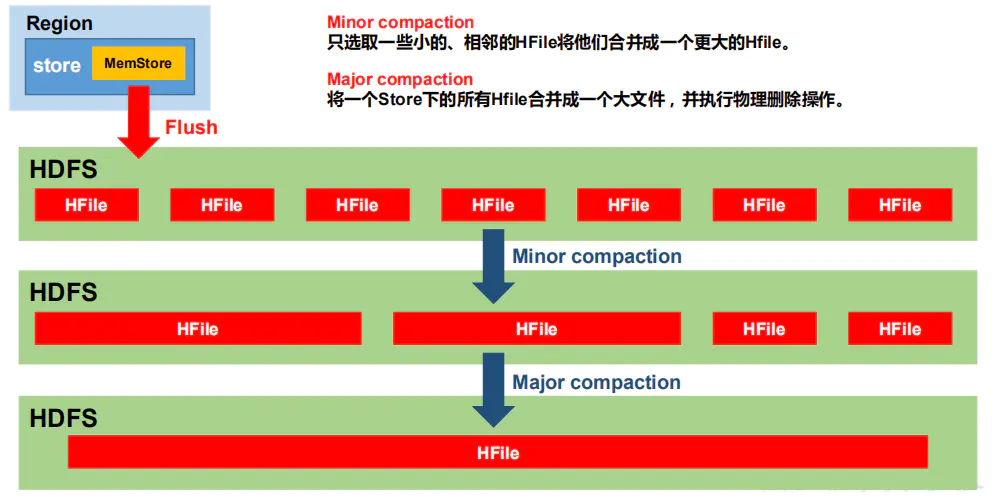
为什么需要执行数据合并?
由于MemStore每次刷写都会生成一个新的HFile,同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能分布在不同的HFile中,因此查询时需要遍历所有的HFile。为了减少HFile的个数,以及清除掉过期和删除的数据,会进行StoreFile Compaction
Compaction分为两种
- Minor Compaction:会将临时的若干较小的HFile合并成一个较大的HFile,但不会清理过期和删除的数据
- Major Compaction:会将一个Store下的所有HFile合并为一个大HFile,并且会清理掉过期和删除的数据
3.2.5. 数据拆分

默认情况下,每个 Table 起初只有一个 Region,随着数据的不断写入,Region 会自动进行拆分。刚拆分时,两个子 Region 都位于当前的 Region Server,但处于负载均衡的考虑,HMaster 有可能会将某个 Region 转移给其他的 Region Server
拆分时机:
- Region中总Store大小超限制:hbase.hregion.max.filesize,该 Region 就会进行拆分(0.94 版本之前)。
- Region中某个Store下所有StoreFile大小超限
4. HBase的扩展性和高可用
HBase 的架构设计使其具备良好的扩展性和高可用性。
| 特性 | 描述 |
|---|
| 扩展性 | HBase 可以通过增加 RegionServer 节点来实现水平扩展。当数据量增长时,HMaster 可以将 Region 划分为更小的 Region,并将其分配到新的 RegionServer 上。 |
| 高可用性 | 通过 Zookeeper 监控集群中的各个节点,HBase 实现了自动故障恢复机制。当一个 RegionServer 发生故障时,HMaster 会将其管理的 Region 重新分配给其他健康的 RegionServer。 |
相关文档:
https://cloud.tencent.com/developer/article/2184702
https://cloud.tencent.com/developer/article/2448014