1.并发编程的幕后
CPU、内存、磁盘IO的速度差异,CPU>内存>磁盘
程序中的一个操作,可能会访问内存也可能还要访问磁盘,根据木桶理论我们能知道此时的性能瓶颈在磁盘
为了平衡三者的差异并合理利用CPU,计算机体系结构、操作系统、编译程序都做了如下贡献:
- CPU增加了缓存(L1、L2、L3也称为寄存器,在JVM规范中也称为工作缓存),用于平衡与内存的速度差异
- 操作系统增加了进程、线程,得以分时复用CPU,进而均衡CPU和IO之间的差异
- 编译程序优化指令执行次序,使得缓存能够更加合理的使用
做出如上贡献的同时,也不可避免的带来了一些并发问题
2.问题一:缓存导致的可见性问题
可见性:一个线程对一个变量的修改,另外一个线程能够立即看到,我们称为可见性
单核时代,所有的线程都在一个CPU上执行,CPU缓存与内存一致性容易得到满足
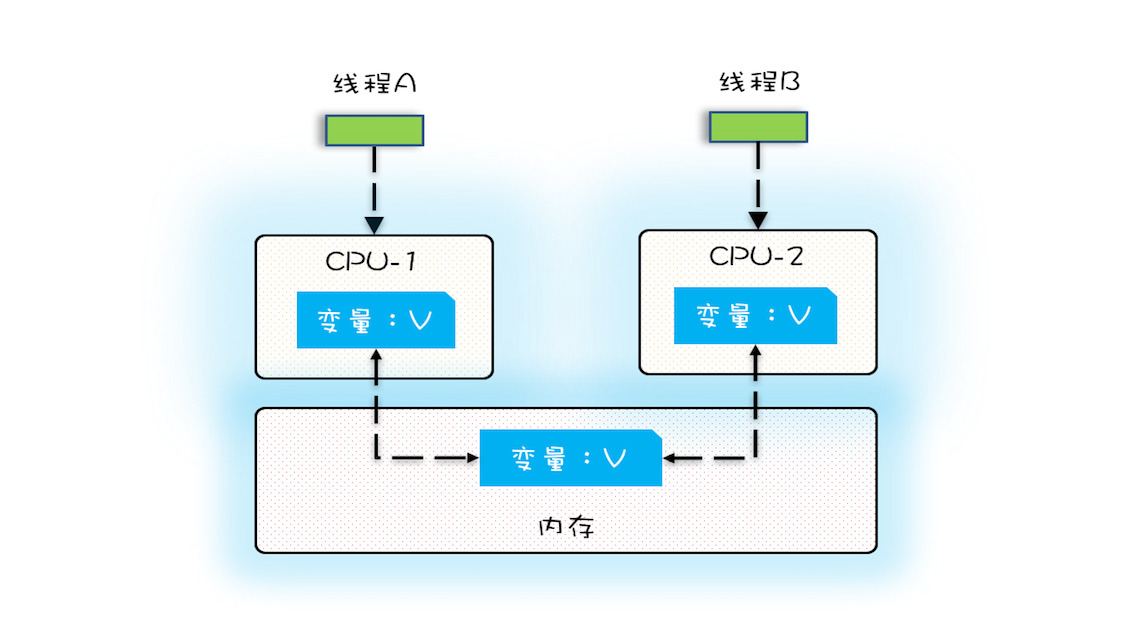
多核时代,每颗CPU都有了自己的缓存,当多个线程在不同的 CPU 上执行时,这些线程操作的是不同的 CPU 缓存,此时就容易造成可见性问题,例如下图的CPU-1对于变量V的调整,线程B就无法及时看到
例:例如平常循环count+=1(读取-修改-写入)的操作,就是可见性的体现,同时也是原子性的体现,因为该自增操作不符合原子性
锁能够同时解决可见性和原子性的问题
3.源头之二:线程切换带来的原子性问题
由于IO太慢,因此操作系统发明了多线程,即便在单CPU我们也能使用多线程,因为分时复用机制(时间片)
因为IO操作比较耗时,如果此时占用CPU的线程等待IO则会浪费CPU资源,此时可将该任务标记为“休眠”状态,此时CPU可以交由其他线程使用,早起操作系统是基于进程进行调度CPU的,由于进程不共享内存空间,所以切换任务会切换内存映射地址,而进程中的所有线程是共享内存空间的,基于线程的切换成本就很低了,所以现在操作系统都基于线程进行任务切换。
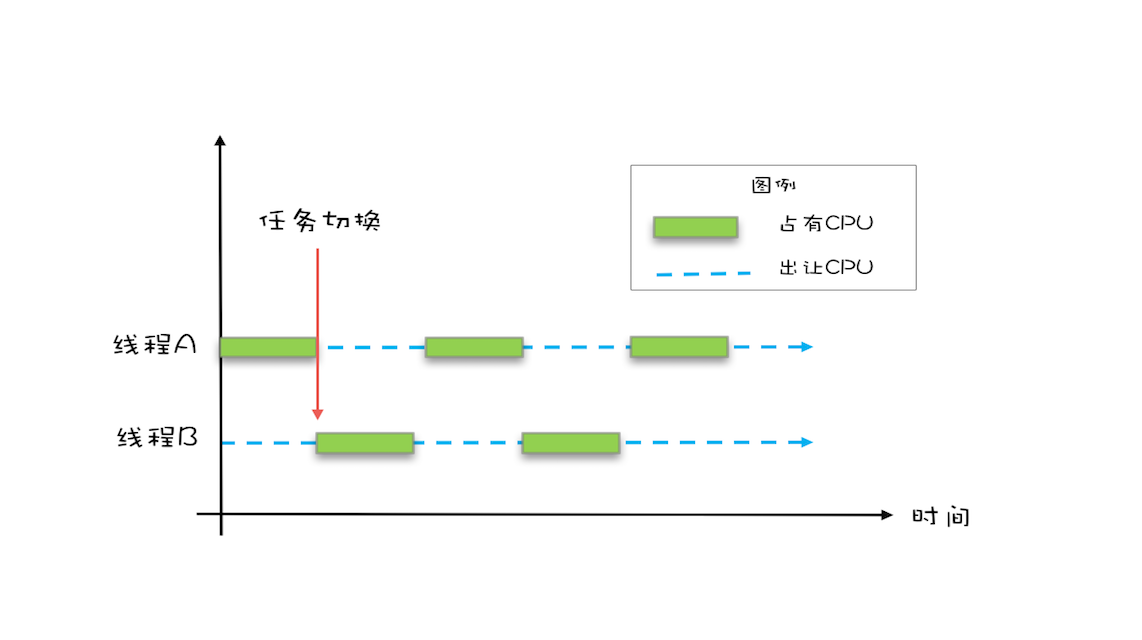
Java并发程序是基于多线程的,自然也涉及到任务切换,而任务切换竟然也是并发编程里诡异 Bug 的源头之一。
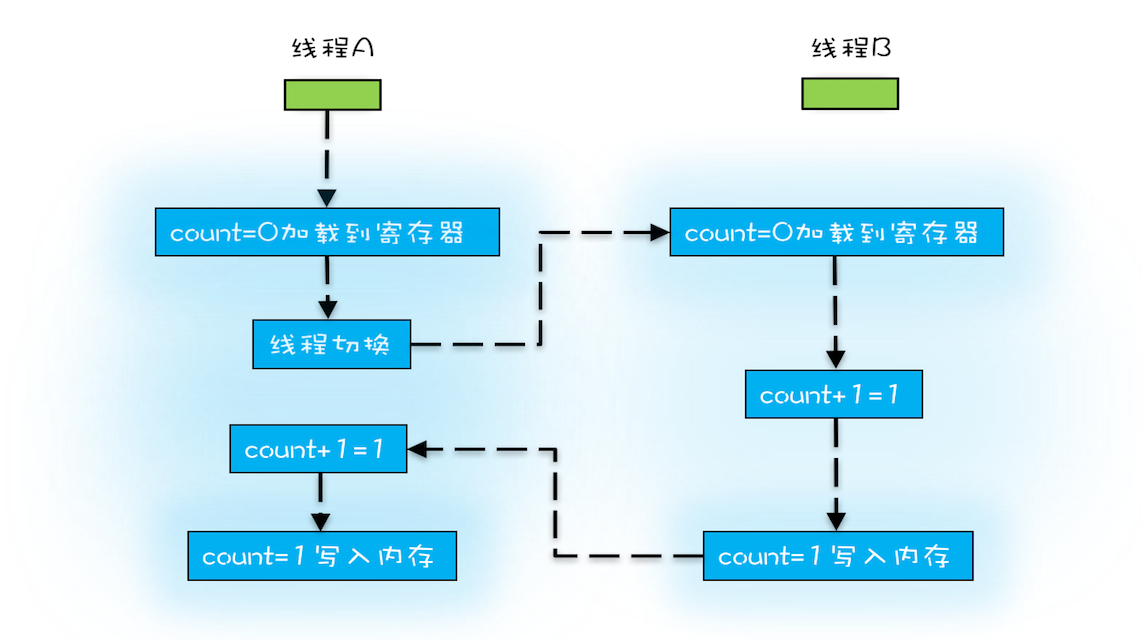
仍然拿count+=1(读取-修改-写入,这里的写入可能是写入CPU的缓存而不是内存)举例,操作系统的切换,可以发生在任意一条指令执行完,因此此时就会导致线程A刚执行到读取就发生了线程切换,此时线程B执行完count+=1操作,再切换到线程A去执行修改与写入操作,此时可能导致最后的count值仍然为1,而不是预期中的2,因此,我们把一个或者多个操作在 CPU 执行的过程中不被中断的特性称为原子性,CPU能保证的原子操作是指令级别的,而不是语言层面的
4.源头之三:编译优化带来的有序性问题
编译器有时候为了优化性能,有时候会改变程序中语句的先后执行顺序,编译器调整了语句的顺序,但是不影响程序的最终结果。不过有时候编译器及解释器的优化可能导致意想不到的 Bug
例如:Java单例模式中先检查-后执行的场景(这个场景也可能会发生原子性问题)
public class Singleton {
static Singleton instance;
static Singleton getInstance(){
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null)
instance = new Singleton();
}
}
return instance;
}
}
这看上去一切都很完美,无懈可击,但实际上这个 getInstance() 方法并不完美。问题出在哪里呢?出在 new 操作上,我们以为的 new 操作应该是:
- 分配一块内存 M;
- 在内存 M 上初始化 Singleton 对象;
- 然后 M 的地址赋值给 instance 变量。
但是实际上优化后的执行路径却是这样的:
- 分配一块内存 M;
- 将 M 的地址赋值给 instance 变量;
- 最后在内存 M 上初始化 Singleton 对象。
优化后会导致什么问题呢?我们假设线程 A 先执行 getInstance() 方法,当执行完指令 2 时恰好发生了线程切换,切换到了线程 B 上;如果此时线程 B 也执行 getInstance() 方法,那么线程 B 在执行第一个判断时会发现 instance != null ,所以直接返回 instance,而此时的 instance 是没有初始化过的,如果我们这个时候访问 instance 的成员变量就可能触发空指针异常
可以关注一下一个new操作所进过的阶段:
分配内存->初始化对象->内存地址赋值给引用
5.总结
上述所说的CPU缓存、CPU的线程切换、编译器的重排序等和我们写并发程序的目的一致,都是为了提高程序性能,合理利用系统资源。