Zookeeper
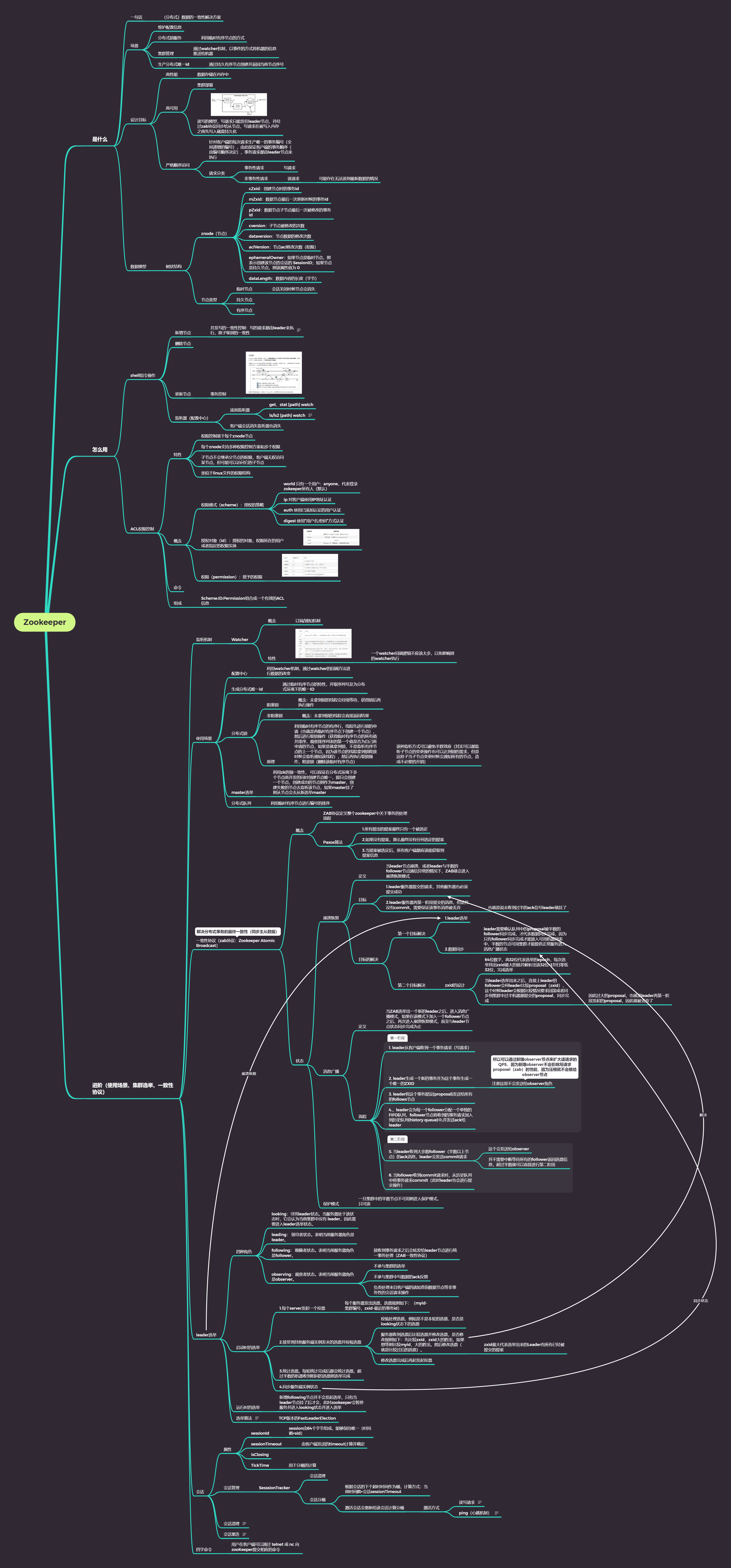
是什么
一句话
场景
-
维护配置信息
-
分布式锁服务
-
集群管理
- 通过watcher机制,以事件的方式将机器的信息推送给机器
-
生产分布式唯一id
设计目标
-
高性能
-
高可用
- 集群部署
- 读写的模型,写请求只能发往leader节点,并经过zab协议同步给从节点,写请求在被写入内存之前先写入磁盘持久化
-
严格顺序访问
数据模型
-
树状结构
-
znode(节点)
- cZxid:创建节点时的事务id
- mZxid:数据节点最后一次更新时候的事务id
- pZxid:数据节点子节点最后一次被修改的事务id
- cversion:子节点被修改的次数
- dataversion:节点数据的修改次数
- aclVersion:节点acl修改次数(权限)
- ephemeralOwner:如果节点是临时节点,则表示创建该节点的会话的 SessionID;如果节点是持久节点,则该属性值为 0
- dataLength:数据内容的长度(字节)
-
节点类型
ACL权限控制
-
特性
- 权限控制基于每个znode节点
- 每个znode支持多种权限控制方案和多个权限
- 子节点不会继承父节点的权限,客户端无权访问某节点,但可能可以访问它的子节点
- 类似于linux文件的权限结构
-
概念
-
命令
-
组成
- Scheme:ID:Permission组合成一个有效的ACL信息
怎么用
shell指令操作
-
新增节点
- 并发写的一致性控制:写的请求都由leader来执行,原子级别的一致性
synchronized (parent) {
Set<String> children = parent.getChildren();
if (children != null) {
if (children.contains(childName)) {
throw new KeeperException.NodeExistsException();
}
}
if (parentCVersion == -1) {
parentCVersion = parent.stat.getCversion();
parentCVersion++;
}
parent.stat.setCversion(parentCVersion);
parent.stat.setPzxid(zxid);
Long longval = convertAcls(acl);
DataNode child = new DataNode(parent, data, longval, stat);
parent.addChild(childName);
nodes.put(path, child);
if (ephemeralOwner != 0) {
HashSet<String> list = ephemerals.get(ephemeralOwner);
if (list == null) {
list = new HashSet<String>();
ephemerals.put(ephemeralOwner, list);
}
synchronized (list) {
list.add(path);
}
}
}
-
删除节点
-
更新节点
-
监听器(配置中心)
-
添加监听器
-
get、stat [path] watch
-
ls/ls2 [path] watch
能够监听节点及其子节点
-
客户端会话消失监听器也消失
进阶(使用场景、集群选举、一致性协议)
监听机制
-
Watcher
-
概念
-
特性
-
- 一个watcher回调逻辑不应该太多,以免影响别的watcher执行
使用场景
-
配置中心
- 利用watcher机制,通过watcher的回调方法进行数据的改变
-
生成分布式唯一id
- 通过临时有序节点的特性,并取序列号及为分布式环境下的唯一ID
-
分布式锁
-
阻塞锁
- 概念:未拿到锁的线程会持续等待,获得锁后再执行操作
-
非阻塞锁
-
原理
-
master选举
- 利用zk的强一致性, 可以保证在分布式环境下多个节点高并发的同时创建节点唯一,即只会创建一个节点,创建成功的节点则作为master,创建失败的节点去监听该节点,如果master挂了则从节点会去从新选举master
-
分布式队列
一致性协议(zab协议:Zookeeper Atomic Broadcast)
-
概念
-
状态
-
崩溃恢复
-
定义
- 当leader节点崩溃、或者leader与半数的follower节点通信异常的情况下,ZAB就会进入崩溃恢复模式
-
目标
- 1.leader服务器提交的请求,其他服务器也必须提交成功
- 2.leader服务器再第一阶段提交的消息,但是并没有commit,需要保证该事务消息被丢弃
-
目标的解决
-
第一个目标解决
-
1.leader选举
-
2.数据同步
- leader需要确认队列中的proposal被半数的follower同步完成,才代表数据同步完成,因为只有follower同步完成才能放入可用机器列表中,半数的节点可用集群才能提供正常服务进入消息广播状态
-
第二个目标解决
-
消息广播
-
定义
- 当ZAB选举出一个新的leader之后,进入消息广播模式,如果在该模式下加入一个follower节点之后,再次进入崩溃恢复模式,直至与leader节点状态同步完成为止
-
流程
-
保护模式
leader选举
会话
四字命令
- 用户在客户端可以通过 telnet 或 nc 向 zooKeeper提交相应的命令