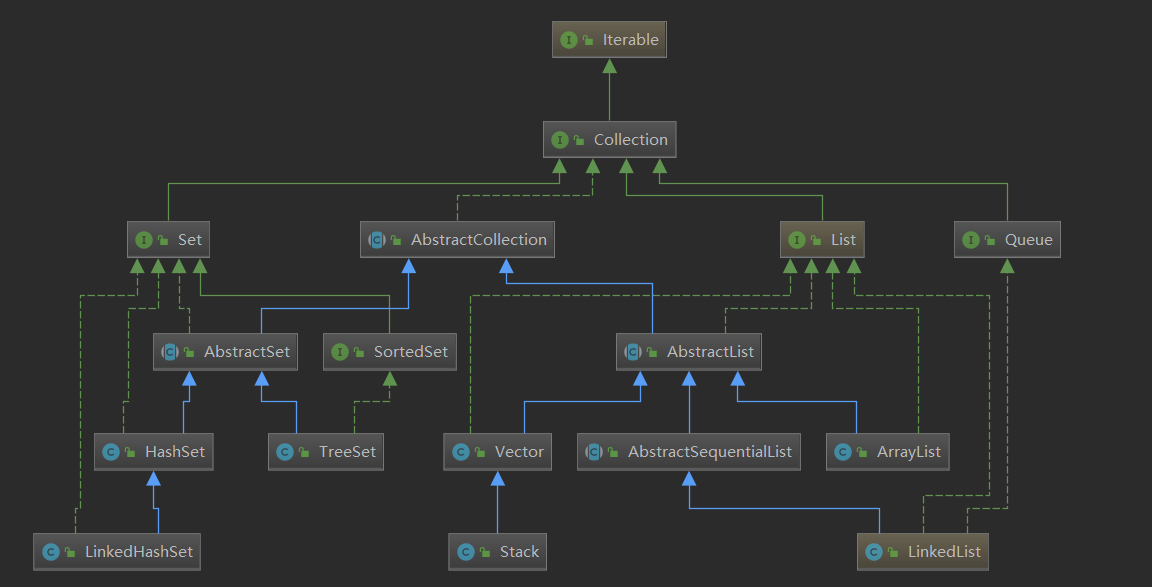
pre:Collection结构类图
1.LinkedList
由族谱我们能够看出LinkedList与ArrayList、Vector都不一样,LinkedList并没有直接作为AbstractList的子类,而是间接通过继承一个叫做AbstractSequentialList的类来作为AbstractList,因此AbstractSequentialList中必定有属于LinkedList独一无二的特性或行为,除此之外。LinkedList还实现了Queue队列类,这又是为什么呢?我们从源码中一探究竟
1.1.先总结
老样子,由于源码解读实在是太长,为了读者这里先将LinkedList源码中比较重要的几个部分再这里总结下,带着问题去看源码,必将事半功倍
(1)AbstractSequentialList类的职责有哪些?
(2)LinkedList的底层存储结构?
(3)LinkedList的CRUD的代码实现
1.2.AbstractSequentialList源码解析
首先我们得明白AbstractSequentialList干了些什么:
-
该类提供了List接口的基本实现,最大程度减少了顺序访问(链表)结构所需要做的工作。对于随机访问的数据,应使用AbstractList
实现顺序访问(链表)结构的增删改查:
public abstract class AbstractSequentialList<E> extends AbstractList<E> {
public void add(int index, E element) {
try {
listIterator(index).add(element);
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
public E remove(int index) {
try {
ListIterator<E> e = listIterator(index);
E outCast = e.next();
e.remove();
return outCast;
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
public E set(int index, E element) {
try {
ListIterator<E> e = listIterator(index);
E oldVal = e.next();
e.set(element);
return oldVal;
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
public E get(int index) {
try {
return listIterator(index).next();
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
}
如果需要实现不同的列表,可以继承此类:
- 要实现普通的列表,需要继承此类,并为listIterator和size方法提供实现
- 对于不可修改的列表,程序员只需实现列表迭代器的hasNext , next , hasPrevious , previous和index方法。
- 对于可修改的列表,程序员应该另外实现列表迭代器的set方法。 对于可变大小的列表,程序员应该另外实现列表迭代器的remove和add方法
public abstract class AbstractSequentialList<E> extends AbstractList<E> {
/**
* 返回列表中的列表迭代器,链表通过列表迭代器来对元素进行CRUD
*/
public abstract ListIterator<E> listIterator(int index);
}
这里我们可以贴下源码:
1.3.LinkedList源码解析
我们都知道,LinkedList底层的数据结构是双向链表,那么双向链表是如何实现的呢?
我们先看下LinkedLIst的成员变量以及节点的结构:
节点结构:
/**
* 从LinkedList的内部类Node我们就可以得知底层是双向链表结构
*/
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
1.3.1.成员变量:
我们看到LinkedList记录了双向链表的头结点和尾结点的位置
/**
* 元素数量,由于LinkedList不涉及扩容,因此没有ArrayList中的length字段
*/
transient int size = 0;
/**
* 指向链表的第一个节点
*/
transient Node<E> first;
/**
* 指向链表的最后一个节点
*/
transient Node<E> last;
1.3.2.构造方法:
LinkedList总共提供了两种构造方法,一个是无参,一个是支持传入一个集合类的构造方法
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this();
//下文中会讲解该方法
addAll(c);
}
接下来我们继续看下LinkedList这个链表的CRUD的基本实现,链表的插入场景一般分为三种,头插法、尾插法、已经根据index随机插入,接下来我们就分别看下这几个插入场景吧
1.3.3.新增
头插法:
public void addFirst(E e) {
linkFirst(e);
}
/**
* 私有方法,头插法真正的实现
*/
private void linkFirst(E e) {
//final修饰,引用初始化后不允许修改
final Node<E> f = first;
//在初始化新增节点的时候就将当前节点的后继指针指向了当前头结点
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
//如果当前头结点为空,则代表当前list没有数据
if (f == null)
//将尾结点的指针指向当前添加的节点
last = newNode;
else
//当前列表的头结点的前继指针指向新增节点
f.prev = newNode;
size++;
modCount++;
}
尾插法,其中LinkedList的add方法就是用的尾插法:
public boolean add(E e) {
//尾插法
linkLast(e);
return true;
}
public void addLast(E e) {
linkLast(e);
}
/**
* protected方法,尾插法真正的实现
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
根据index进行插入:
链表的插入步骤如下,记新增节点newNode,插入节点succ,插入节点succ的前继节点pred:
- 获得当前插入节点succ的后继节点pred
- 将新增节点newNode的前继节点、后继节点分别指向插入节点succ及其前继节点pred
- 判断插入节点succ的前继节点是否为空,为空则代表当前插入节点为头节点,则将first指向新节点newNode
- 不为空则将插入节点succ的前继、pred节点的后继指向新增节点newNode
public void add(int index, E element) {
checkPositionIndex(index);
//如果当前插入位置就是队尾,则直接使用尾插法
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
/**
*
*/
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
1.3.4.删除
删除操作类似于新增操作,也分为从尾部删除、头部删除、中间删除某个元素,前两种比较简单,只需要将LinkedList的头、尾指针指向头结点或尾结点的前驱或后继节点即可,为了方便GC,需要额外做些处理
从任意位置删除的步骤如下:
记删除节点x,前驱节点prev,后继节点next
- 先定位到删除的节点
- 判断是否是头、尾节点,如果是则将后头尾节点指向前驱/后继节点
- 如果不是,则将前驱节点的next指针指向后继节点next,将后继节点next的prev指针指向前驱节点prev
- x的元素置为null
//默认的删除是采取头部删除public E remove() { return removeFirst();}public boolean remove(Object o) { if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { //主要的删除方法 unlink(x); return true; } } } else { //遍历链表得到元素 for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); return true; } } } return false;} E unlink(Node<E> x) { // assert x != null; final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; if (prev == null) { first = next; } else { prev.next = next; x.prev = null; } if (next == null) { last = prev; } else { next.prev = prev; x.next = null; } x.item = null; size--; modCount++; return element; }
1.3.5.修改
LinkedList的修改使用的是set方法,但是修改指定index位置的元素时,由于不能像数组可以随机读写,因此是能采取遍历的形式匹配元素,但是LinkedList由于拥有头尾指针,因此可以将LinkedList二分,如果处于左半区则从头结点开始遍历,右半区则从尾节点开始遍历.因此
LinkedList通过node()方法得到具体节点
步骤如下:
代码如下:
public E set(int index, E element) { checkElementIndex(index); //遍历链表得到节点 Node<E> x = node(index); E oldVal = x.item; x.item = element; return oldVal;}Node<E> node(int index) { // assert isElementIndex(index); //判断index处于哪个半区则从哪边开始遍历 if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; } }
1.3.6.查找
与修改元素类似,遍历链表,查找到指定位置的元素
public E get(int index) { checkElementIndex(index); return node(index).item;}
1.3.7.队列的相关方法
不管是线性结构(数组)还是链式结构(链表)都能够实现队列(FIFO),并且Linked也实现了Queue接口,自然也实现了队列的相关方法。
由于队列的方法实现比较简单,基本就是头插法、尾插法、头部出队、头部入队,都是通过头尾指针来实现
1.3.8.内部类
与ArrayList类似,ListItr为迭代器容器类,用于遍历所持有的元素,会根据modCount来判断链表是否被修改,否则抛出异常
private class ListItr implements ListIterator<E> {}